
前言
相信很多做Android或是Java研發的同學對RxJava應該都早有耳聞了,尤其是在Android開發的圈子里,RxJava漸漸開始廣為流行。同樣有很多同學已經開始在自己的項目中使用RxJava。它能夠幫助我們在處理異步事件時能夠省去那些復雜而繁瑣的代碼,尤其是當某些場景邏輯中回調中嵌入回調時,使用RxJava依舊能夠讓我們的代碼保持極高的可讀性與簡潔性。不僅如此,這種基于異步數據流概念的編程模式事實上同樣也能廣泛運用在移動端這種包括網絡調用、用戶觸摸輸入和系統彈框等在內的多種響應驅動的場景。那么現在,就讓我們一起分析一下RxJava的響應流程吧。
(本文基于RxJava-1.1.3)
用法
首先來看一個簡單的例子:
Observable.create(new Observable.OnSubscribe<String>() {
@Override
public void call(Subscriber<? super String> subscriber) {
subscriber.onNext("onNext");
subscriber.onCompleted();
}
}).map(new Func1<String, String>() {
@Override
public String call(String s) {
return s + " -> Xepher";
}
}).subscribe(new Subscriber<String>() {
@Override
public void onCompleted() {
System.out.println("--- onCompleted ---");
}
@Override
public void onError(Throwable e) {
System.out.println("onError");
}
@Override
public void onNext(String s) {
System.out.println("subscriber -> " + s);
}
});
運行結果為:
subscriber -> onNext -> Xepher
--- onCompleted ---
從結果中我們不難看出整體的調用流程:
首先通過調用Observable.create()方法生成一個被觀察者,緊接著在這里我們又調用了map()方法對原被觀察者進行數據流的變換操作,生成一個新的被觀察者(為何是新的被觀察者后文會講),最后調用subscribe()方法,傳入我們的觀察者,這里觀察者訂閱的則是調用map()之后生成的新被觀察者。
在整個過程中我們會注意到三個主角:Observable、OnSubscribe、Subscriber,所有的操作都是圍繞它們進行的。不難看出這里三個角色的分工:
- Observable:被觀察者的來源,亦或說是被觀察者本身
- OnSubscribe:用來通知觀察者的不同行為
- Subscriber:觀察者,通過實現對應方法來產生具體的處理。
所以接下來我們以這三個角色為中心來分析具體的流程。
分析
一、訂閱過程
首先我們進入Observable.create()看看:
public static <T> Observable<T> create(OnSubscribe<T> f) {
return new Observable<T>(hook.onCreate(f));
}
這里調用構造函數生成了一個Observable對象并將傳入的OnSubscribe賦給自己的成員變量onsubscribe,等等,這個hook是從哪里冒出來的?我們向上找:
static final RxJavaObservableExecutionHook hook = RxJavaPlugins.getInstance().getObservableExecutionHook();
RxJavaObservableExecutionHook這個抽象Proxy類默認對OnSubscribe對象不做任何處理,不過通過繼承該類并重寫onCreate()等方法我們可以對這些方法對應的時機做一些額外處理比如打Log或者一些數據收集方面的工作。
到目前最初始的被觀察者已經生成了,我們再來看看觀察者這邊。我們知道通過調用observable.subscribe()方法傳入一個觀察者即構成了觀察者與被觀察者之間的訂閱關系,那么這內部又是如何實現的呢?看代碼:
public final Subscription subscribe(Subscriber<? super T> subscriber) {
return Observable.subscribe(subscriber, this);
}
private static <T> Subscription subscribe(Subscriber<? super T> subscriber, Observable<T> observable) {
... ...
subscriber.onStart();
if (!(subscriber instanceof SafeSubscriber)) {
subscriber = new SafeSubscriber<T>(subscriber);
}
try {
hook.onSubscribeStart(observable, observable.onSubscribe).call(subscriber);
return hook.onSubscribeReturn(subscriber);
} catch (Throwable e) {
Exceptions.throwIfFatal(e);
... ...
return Subscriptions.unsubscribed();
}
}
這里我們略去部分無關代碼看主要部分,subscribe.onStart()默認空實現我們暫且不用管它,對于傳進來的subscriber要包裝成SafeSubscriber,這個SafeSubscriber對原來的subscriber的一系列方法做了更完善的處理,包括:onError()與onCompleted()只會有一個被執行;保證一旦onError()或者onCompleted()被執行,將不再能再執onNext()等情況。這里封裝為SafeSubscriber之后,調用onSubscribe.call(),并將subscriber傳入,這樣就完成了一次訂閱。

顯而易見,Subscriber作為觀察者,在訂閱行為完成后,其具體行為在整個鏈式調用中起著至關重要的作用,我們來看看它內部的構成的主要部分:
public abstract class Subscriber<T> implements Observer<T>, Subscription {
private static final Long NOT_SET = Long.MIN_VALUE;
private final SubscriptionList subscriptions; //當前Subscriber所持有的“訂閱”事件集
private final Subscriber<?> subscriber;
private Producer producer;//用于規定從Observable傳來的數據流的總量
private long requested = NOT_SET;
... ...
protected Subscriber(Subscriber<?> subscriber, boolean shareSubscriptions) {
this.subscriber = subscriber;
this.subscriptions = shareSubscriptions && subscriber != null ? subscriber.subscriptions : new SubscriptionList();
}
@Override
public final void unsubscribe() {
subscriptions.unsubscribe();
}
... ...
protected final void request(long n) {
if (n < 0) {
throw new IllegalArgumentException("number requested cannot be negative: " + n);
}
Producer producerToRequestFrom = null;
synchronized (this) {
if (producer != null) {
producerToRequestFrom = producer;
} else {
addToRequested(n);
return;
}
}
producerToRequestFrom.request(n);
}
... ...
public void setProducer(Producer p) {
long toRequest;
boolean passToSubscriber = false;
synchronized (this) {
toRequest = requested;
producer = p;
if (subscriber != null) {
if (toRequest == NOT_SET) {
passToSubscriber = true;
}
}
}
if (passToSubscriber) {
subscriber.setProducer(producer);
} else {
if (toRequest == NOT_SET) {
producer.request(Long.MAX_VALUE);
} else {
producer.request(toRequest);
}
}
}
}
每個Subscriber都持有一個SubscriptionList,這個list保存的是所有該觀察者的訂閱事件,同時Subscriber也對應實現了Subscription接口,當這個Subscriber取消訂閱的時候會將持有事件列表中的所有Subscription取消訂閱,并且從此不再接受任何訂閱事件。
同時,通過Producer可以去限定該Subscriber所接收的數據流的總量,這個限制量其實是加在Subscriber.onNext()方法上的,onComplete()、onError()則不會受到其影響。
因為是底層抽象類,onNext()、onComplete()、onError()統一不在這里處理。
二、變換過程
在收到Observable的消息之前我們有可能會對數據流進行處理,例如map()、flatMap()、deBounce()、buffer()等方法,本例中我們用了map()方法,它接收了原被觀察者發射的數據并將通過該方法返回的結果作為新的數據發射出去,相當于做了一層中間轉化:
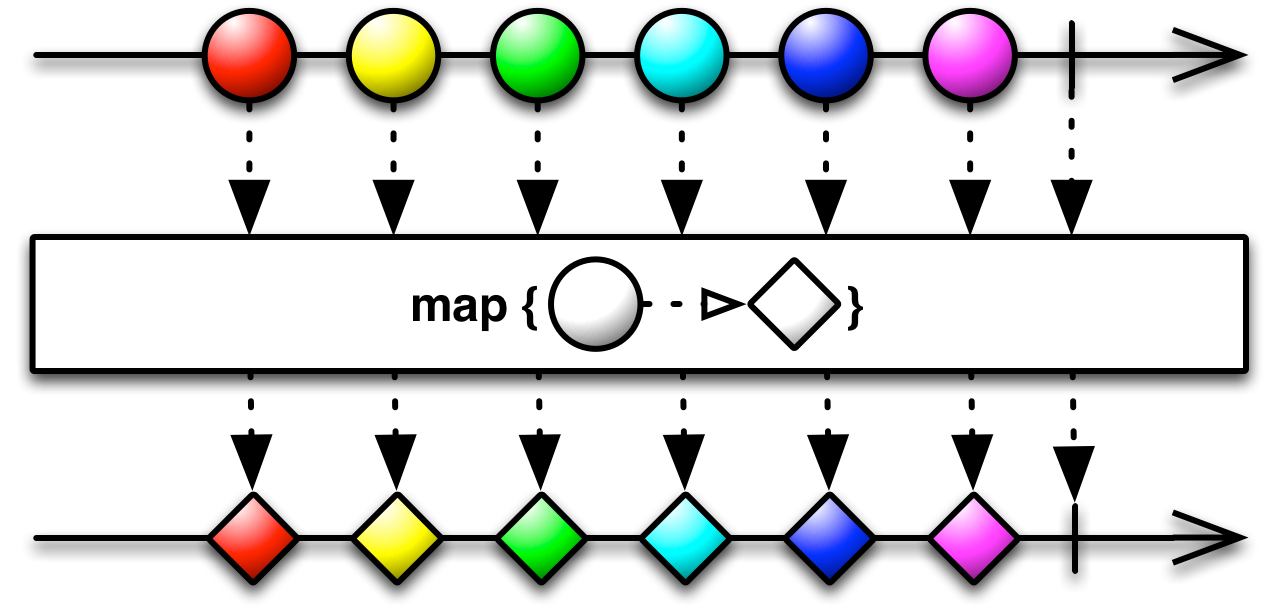
我們接著看這個轉化過程:
public final <R> Observable<R> map(Func1<? super T, ? extends R> func) {
return lift(new OperatorMap<T, R>(func));
}
這里是通過一個lift()方法實現的,再查看其他的轉化方法發現內部也都使用lift()實現的,看來這個lift()就是關鍵所在了,不過不急,我們先來看看這個OperationMap是什么:
public final class OperatorMap<T, R> implements Operator<R, T> {
final Func1<? super T, ? extends R> transformer;
public OperatorMap(Func1<? super T, ? extends R> transformer) {
this.transformer = transformer;
}
@Override
public Subscriber<? super T> call(final Subscriber<? super R> o) {
return new Subscriber<T>(o) {
@Override
public void onCompleted() {
o.onCompleted();
}
@Override
public void onError(Throwable e) {
o.onError(e);
}
@Override
public void onNext(T t) {
try {
o.onNext(transformer.call(t));
} catch (Throwable e) {
Exceptions.throwOrReport(e, this, t);
}
}
};
}
}
OperationMap實現了Operator接口的call()方法,該方法接受外部傳入的觀察者,并將其作為參數構造出了一個新的觀察者,我們不難發現o.onNext(transformer.call(t));這一句起了至關重要的作用,這里的接口transformer將泛型T轉化為泛型R:
public interface Func1<T, R> extends Function {
R call(T t);
}
這樣之后,再將轉換后的數據傳回至原觀察者的onNext()方法,就完成了觀察數據流的轉化,但是你應該也注意到了,我們用來做轉換的這個新的觀察者并沒有實現訂閱被觀察者的操作,這個訂閱操作又是在哪里實現的呢?答案就是接下來的lift():
public final <R> Observable<R> lift(final Operator<? extends R, ? super T> operator) {
return new Observable<R>(new OnSubscribe<R>() {
@Override
public void call(Subscriber<? super R> o) {
try {
Subscriber<? super T> st = hook.onLift(operator).call(o);
try {
st.onStart();
onSubscribe.call(st);
} catch (Throwable e) {
Exceptions.throwIfFatal(e);
st.onError(e);
}
} catch (Throwable e) {
Exceptions.throwIfFatal(e);
o.onError(e);
}
}
});
}
在這里我們新生成了一個Observable對象,在這個新對象的onSubscribe成員的call()方法中我們通過operator.call()拿到之前生成的未產生訂閱的觀察者st,之后將它作為參數傳入一開始的onSubscribe.call()中,即完成了這個中間訂閱的過程。
現在我們將整個流程梳理一下:
1、一次map()變換
2、根據Operator實例生成新的Subscriber
3、通過lift()生成新的Observable
4、原Subscriber訂閱新的Observavble
5、新的Observable中onSubscribe通知新Subscriber訂閱原Observable
6、新Subscriber將消息傳給原Subscriber。
為了便于理解,這里借用一下扔物線的圖:

以上就是一次
map() 變換的流程,事實上多次map()也是同樣道理:最外層的目標Subscriber發生訂閱行為后,onSubscribe.onNext()會逐層嵌套調用,直至初始Observable被最底層的Subscriber訂閱,通過Operator的一層層變化將消息傳到目標Subscriber。再次祭出扔物線的圖:
至于其他的多種變化的實現流程也都很類似,借助于Operator的不同實現來達到變換數據流的目的。例如其中的
flatMap(),它需要進行兩次lift(),其中第二次是OperationMerge,將轉換成的每一個Observable數據流通過InnerSubscriber這個紐帶訂閱后,在InnerSubscriber的onNext()中拿到R,再通過傳入的parent(也就是原MergeSubscriber)將它們全部發射(emit)出去,由最外層我們傳入的Subscriber統一接收,這樣就完成了 T => Observable<R> => R 的轉化:
// MergeSubscriber
@Override
public void onNext(Observable<? extends T> t) {
if (t == null) {
return;
}
if (t instanceof ScalarSynchronousObservable) {
tryEmit(((ScalarSynchronousObservable<? extends T>)t).get());
} else {
InnerSubscriber<T> inner = new InnerSubscriber<T>(this, uniqueId++);
addInner(inner);
t.unsafeSubscribe(inner);
emit();
}
}
// InnerSubscriber
static final class InnerSubscriber<T> extends Subscriber<T> {
final MergeSubscriber<T> parent;
final long id;
... ...
public InnerSubscriber(MergeSubscriber<T> parent, long id) {
this.parent = parent;
this.id = id;
}
... ...
@Override
public void onNext(T t) {
parent.tryEmit(this, t);
}
}
除此之外,還有許多各式各樣的操作符,如果它們還不能滿足你的需要,你也可以通過實現Operator接口定制新的操作符。靈活運用它們往往能達到事半功倍的效果,比如通過使用sample()、debounce()等操作符有效避免backpressure的需要等等,這里就不一一介紹了。
三、線程切換過程
從上文中我們知道了RxJava能夠幫助我們對數據流進行靈活的變換,以達到鏈式結構操作的目的,然而它的強大不止于此。下面我們就來看看它的又一利器,調度器Scheduler:
就像我們所知道的,Scheduler是給Observable數據流添加多線程功能所準備的,一般我們會通過使用subscribeOn()、observeOn()方法傳入對應的Scheduler去指定數據流的每部分操作應該以何種方式運行在何種線程。對于我們而言,最常見的莫過于在非主線程獲取并處理數據之后在主線程更新UI這樣的場景了:
Observable.create(... ...)
... ...
.subscribeOn(Schedulers.io())
... ...
.observeOn(AndroidSchedulers.mainThread())
... ...
.subscribe();
這是我們十分常見的調用方法,一氣呵成就把不同線程之間的處理都搞定了,因為是鏈式所以結構也很清晰,我們現在來看看這其中的線程切換流程。
1、subscribeOn()
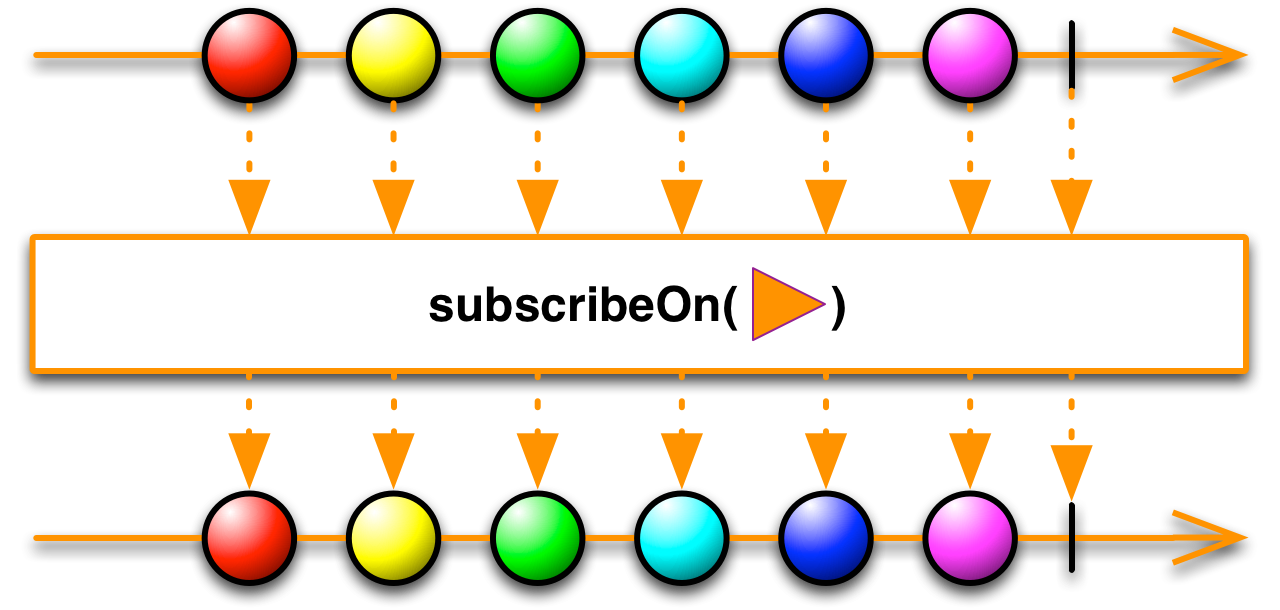
當我們調用
subscribeOn()的時候:
public final Observable<T> subscribeOn(Scheduler scheduler) {
if (this instanceof ScalarSynchronousObservable) {
return ((ScalarSynchronousObservable<T>)this).scalarScheduleOn(scheduler);
}
return create(new OperatorSubscribeOn<T>(this, scheduler));
}
可以看到這里也是調用了create()去生成一個Observable,而OperatorSubscribeOn則是實現了OnSubscribe接口,同時將原始的Observable和我們需要的scheduler傳入:
public final class OperatorSubscribeOn<T> implements OnSubscribe<T> {
final Scheduler scheduler;
final Observable<T> source; //原Observable
public OperatorSubscribeOn(Observable<T> source, Scheduler scheduler) {
this.scheduler = scheduler;
this.source = source;
}
@Override
public void call(final Subscriber<? super T> subscriber) {
final Worker inner = scheduler.createWorker();
subscriber.add(inner);
inner.schedule(new Action0() {
@Override
public void call() {
final Thread t = Thread.currentThread();
Subscriber<T> s = new Subscriber<T>(subscriber) {
@Override
public void onNext(T t) {
subscriber.onNext(t);
}
@Override
public void onError(Throwable e) {
try {
subscriber.onError(e);
} finally {
inner.unsubscribe();
}
}
@Override
public void onCompleted() {
try {
subscriber.onCompleted();
} finally {
inner.unsubscribe();
}
}
@Override
public void setProducer(final Producer p) {
subscriber.setProducer(new Producer() {
@Override
public void request(final long n) {
if (t == Thread.currentThread()) {
p.request(n);
} else {
inner.schedule(new Action0() {
@Override
public void call() {
p.request(n);
}
});
}
}
});
}
};
source.unsafeSubscribe(s);
}
});
}
}
可以看出來,這里對subscriber的處理與前文中OperatorMap中call()對subscriber的處理很相似。在這里我們同樣會根據傳入的subscriber構造出新的Subscriber s,不過這一系列的過程大部分都是由worker通過schedule()去執行的,從后面setProducer()中對于線程的判斷,再結合subscribeOn()方法的目的我們能大概推測出,這個worker在一定程度上就相當于一個新線程的代理執行者,schedule()所實現的與Thread類中run()應該十分類似。我們現在來看看這個worker的執行過程。
首先從Schedulers.io()進入:
Scheduler io = RxJavaPlugins.getInstance().getSchedulersHook().getIOScheduler();
if (io != null) {
ioScheduler = io;
} else {
ioScheduler = new CachedThreadScheduler();
}
這個通過hook拿到scheduler的過程我們先不管,直接進CachedThreadScheduler,看它的createWorker()方法:
@Override
public Worker createWorker() {
return new EventLoopWorker(pool.get());
}
這里的pool是一個原子變量引用AtomicReference,所持有的則是CachedWorkerPool,因而這個pool顧名思義就是用來保存worker的緩存池啦,我們從緩存池里拿到需要的worker并作了一層封裝成為EventLoopWorker:
// CachedWorkerPool
ThreadWorker get() {
if (allWorkers.isUnsubscribed()) {
return SHUTDOWN_THREADWORKER;
}
while (!expiringWorkerQueue.isEmpty()) {
ThreadWorker threadWorker = expiringWorkerQueue.poll();
if (threadWorker != null) {
return threadWorker;
}
}
// No cached worker found, so create a new one.
ThreadWorker w = new ThreadWorker(WORKER_THREAD_FACTORY);
allWorkers.add(w);
return w;
}
在這里我們終于發現目標ThreadWorker,它繼承自NewThreadWorker,之前的schedule()方法最終都會到這個scheduleActual()方法里:
// NewThreadWorker
@Override
public Subscription schedule(final Action0 action) {
return schedule(action, 0, null);
}
... ...
public ScheduledAction scheduleActual(final Action0 action, long delayTime, TimeUnit unit) {
Action0 decoratedAction = schedulersHook.onSchedule(action);
ScheduledAction run = new ScheduledAction(decoratedAction);
Future<?> f;
if (delayTime <= 0) {
f = executor.submit(run);
} else {
f = executor.schedule(run, delayTime, unit);
}
run.add(f);
return run;
}
這里我們看到了executor線程池,我們用Schedulers.io()最終實現的線程切換的本質就在這里了。現在再結合之前的過程我們從頭梳理一下:

在subscribeOn()時,我們會新生成一個Observable,它的成員
onSubscribe會在目標Subscriber訂閱時使用傳入的Scheduler的worker作為線程調度執行者,在對應的線程中通知原始Observable發送消息給這個過程中臨時生成的Subscriber,這個Subscriber又會通知到目標Subscriber,這樣就完成了subscribeOn()的過程。
2、observeOn()
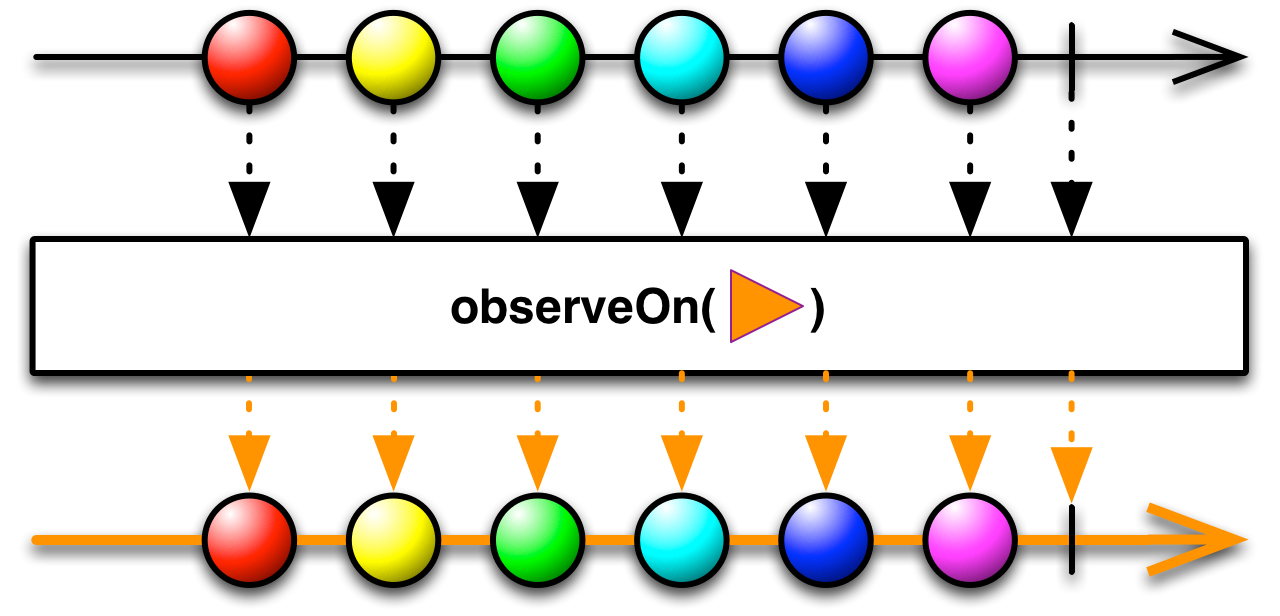
下面我們接著來看看observeOn():
// Observable
public final Observable<T> observeOn(Scheduler scheduler, boolean delayError, int bufferSize) {
if (this instanceof ScalarSynchronousObservable) {
return ((ScalarSynchronousObservable<T>)this).scalarScheduleOn(scheduler);
}
return lift(new OperatorObserveOn<T>(scheduler, delayError, bufferSize));
}
我們直接看最終調用的部分,可以看到這里又是一個lift(),在這里傳入了OperatorObserveOn,它與OperatorSubscribeOn不同,是一個Operator(Operator的功能我們上文中已經講過就不贅述了),它構造出了新的觀察者ObserveOnSubscriber并實現了Action0接口:
public ObserveOnSubscriber(Scheduler scheduler, Subscriber<? super T> child, boolean delayError, int bufferSize) {
this.child = child;
this.recursiveScheduler = scheduler.createWorker();
... ...
}
這個ObserveOnSubscriber拿到了目標Scheduler recursiveScheduler 和目標Subscriber child,并在它自己的onNext()、onError()、onComplete()方法中作了schedule()的線程變化處理:
// ObserveOnSubscriber
@Override
public void onNext(final T t) {
... ...
schedule();
}
@Override
public void onCompleted() {
... ...
schedule();
}
@Override
public void onError(final Throwable e) {
... ...
schedule();
}
protected void schedule() {
if (counter.getAndIncrement() == 0) {
recursiveScheduler.schedule(this);//實現了Action0接口,在recursiveScheduler對應線程中作精細處理
}
}
@Override
public void call() {
... ...
//檢查數據流狀態,會在這里進行onComplete()或者onError()的流程
if (checkTerminated(done, empty, localChild, q)) {
return;
}
localChild.onNext(localOn.getValue(v));
... ...
}
可以看出來,這里ObserveOnSubscriber所有的發送給目標Subscriber child的消息都被切換到了recursiveScheduler的線程作處理,也就達到了將線程切回的目的。
總結observeOn()整體流程如下:

對比
subscribeOn()和observeOn()這兩個過程,我們不難發現兩者的區別:subscribeOn()將初始Observable的訂閱事件整體都切換到了另一個線程;而observeOn()則是將初始Observable發送的消息切換到另一個線程通知到目標Subscriber。前者把** “訂閱 + 發送” 的切換了一個線程,后者把 “發送” ** 切換了一個線程。所以,我們的代碼中所實現的功能其實是:
... ...
.subscribeOn(Schedulers.io())//將“訂閱”、“發送”都切換到Schedulers.io()對應的線程
... ...
.observeOn(AndroidSchedulers.mainThread())////將“發送”再切換回到AndroidSchedulers.mainThread()對應的線程
這樣就能很容易實現耗時任務在子線程操作,在主線程作更新操作等這些常見場景的功能啦。
四、其他角色
Subject
Subject在Rx系列是一個比較特殊的角色,它繼承了Observable的同時也實現了Observer接口,也就是說它既可作為觀察者,也可作為被觀察者,他一般被用來作為連接多個不同Observable、Observer之間的紐帶。可能你會奇怪,我們不是已經有了像map()、flatMap()這類的操作符去變化 Observable數據流了嗎,為什么還要引入Subject這個東西呢?這是因為Subject所承擔的工作并非是針對Observable數據流內容的轉換連接,而是數據流本身在Observable、Observer之間的調度。光這么說可能還是很模糊,我們舉個《RxJava Essentials》中的例子:
PublishSubject<String> stringPublishSubject = PublishSubject.create();
Subscription subscriptionPrint = stringPublishSubject.subscribe(new Observer<String>() {
@Override
public void onCompleted() {
System.out.println("Observable completed");
}
@Override
public void onError(Throwable e) {
System.out.println("Oh,no!Something wrong happened!");
}
@Override
public void onNext(String message) {
System.out.println(message);
}
});
stringPublishSubject.onNext("Hello World");
我們通過create()創建了一個PublishSubject,觀察者成功訂閱了這個subject,然而這個subject卻沒有任何數據要發送,我們只是知道他未來會發送的會是String值而已。之后,當我們調用subject.onNext()時,消息才被發送,Observer的onNext()被觸發調用,輸出了"Hello World"。
這里我們注意到,當訂閱事件發生時,我們的subject是沒有產生數據流的,直到它發射了"Hello World",數據流才開始運轉,試想我們如果將訂閱過程和subject.onNext()調換一下位置,那么Observer就一定不會接受到"Hello World"了(這不是廢話嗎- -|||),因而這也在根本上反映了Observable的冷熱區別。
一般而言,我們的Observable都屬于Cold Observables,就像看視頻,每次點開新視頻我們都要從頭開始播放;而Subject則默認屬于Hot Observables,就像看直播,視頻數據永遠都是新的。
基于這種屬性,Subject自然擁有了對接收到的數據流進行選擇調度等的能力了,因此,我們對于Subject的使用也就通常基于如下的思路:
//接收數據流
Observable.create(...).subscribe(mSubject);
//選擇調度并發射數據給觀察者
mSubject.subscribe(...);
在前面的例子里我們用到的是PublishSubject,它只會把在訂閱發生的時間點之后來自原始Observable的數據發射給觀察者。等一下,這功能聽起來是不是有些似曾相識呢?
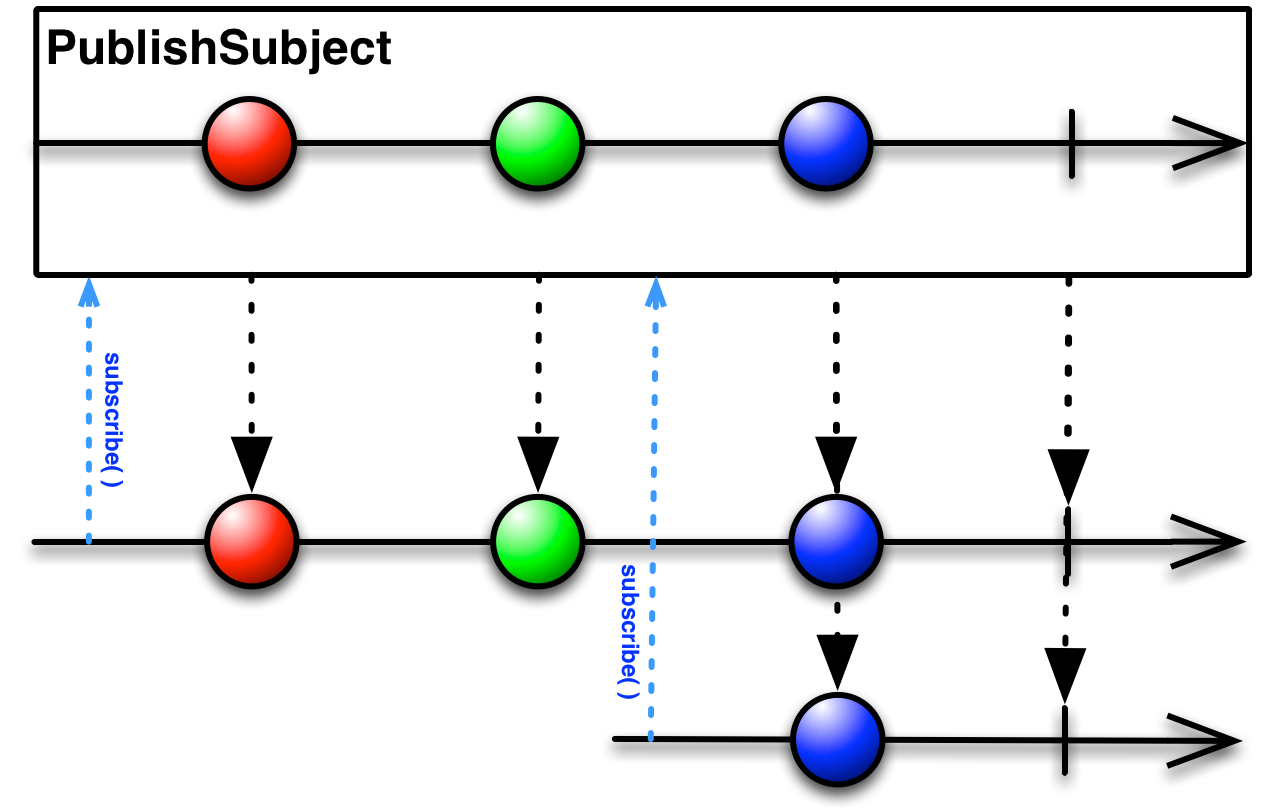
沒錯,就是EventBus和Otto。
(RxJava的出現慢慢讓Otto退出了舞臺,現在Otto的Repo已經是Deprecated狀態了,而EventBus依舊堅挺)
基于RxJava的觀察訂閱取消的能力和
PublishSubject的功能,我們十分容易就能寫出實現了最基本功能的簡易事件總線框架:
public class RxBus {
private static volatile RxBus mInstance;
//為了保證線程安全,包裝為SerializedSubject
private final Subject<Object, Object> mBus = new SerializedSubject<>(PublishSubject.create());
private final CompositeSubscription mSubscriptions = new CompositeSubscription();
private RxBus() {}
public static RxBus getDefault() {
if (mInstance == null) {
synchronized (RxBus.class) {
if (mInstance == null) {
mInstance = new RxBus();
}
}
}
return mInstance;
}
//發送事件
public void post(Object o) {
mBus.onNext(o);
}
//接收事件
public void subscribe(Action1 action) {
mSubscriptions.add(mBus.subscribe(action));
}
//取消所有訂閱事件
public void unSubscribe() {
mSubscriptions.unsubscribe();
}
}
當然Subject還有其他如BehaviorSubject、ReplaySubject、AsyncSubject等類型,大家可以去看官方文檔,寫得十分詳細,這里就不介紹了。
后記
前面相信最近這段日子里,提到RxJava,大家就會想到Google最近剛剛開源的Agera。Agera作為專門為Android打造的Reactive Programming框架,難免會被拿來與RxJava做對比。本文前面RxJava的主體流程分析已近尾聲,現在我們再來看看Agera這東東又是怎么一回事。

首先先上結論:RxJava和Agera的關系
Agera最初是為了Google Play Movies而開發的一個內部框架,現在開源出來了,它雖然是在RxJava之后才出現,但是完全獨立于RxJava,與它沒有任何關系(只不過開源的時間十分微妙罷了- -)。 與RxJava比起來,Agera更加專注于Android的生命周期,而RxJava則更加純粹地面向Java平臺而非Android。
也許你可能會問:“那么RxAndroid呢,不是還有它嗎?”事實上,RxAndroid早在1.0版本的時候就進行了很大的重構,很多模塊被拆分到其他的項目中去了,同時也刪除了部分代碼,僅存下來的部分多是和Android線程相關的部分,比如
AndroidSchedulers、MainThreadSubscription等。鑒于這種情況,我們暫且不去關注RxAndroid,先把目光放在Agera上。
同樣也是基于觀察者模式,Agera和RxJava的角色分類大致相似,在Agera中,主要角色有兩個:Observable(被觀察者)、Updatable(觀察者)。
public interface Observable {
/**
* Adds {@code updatable} to the {@code Observable}.
*
* @throws IllegalStateException if the {@link Updatable} was already added or if it was called
* from a non-Looper thread
*/
void addUpdatable(@NonNull Updatable updatable);
/**
* Removes {@code updatable} from the {@code Observable}.
*
* @throws IllegalStateException if the {@link Updatable} was not added
*/
void removeUpdatable(@NonNull Updatable updatable);
}
public interface Updatable {
/**
* Called when an event has occurred.
*/
void update();
}
是的,相較于RxJava中的Observable,Agera中的Observable只是一個簡單的接口,也沒有泛型的存在,Updatable亦是如此,這樣我們要如何做到消息的傳遞呢?這就需要另外一個接口了:
public interface Supplier<T> {
/**
* Returns an instance of the appropriate type. The returned object may or may not be a new
* instance, depending on the implementation.
*/
@NonNull
T get();
}
終于看到了泛型T,我們的消息的傳遞能力就是依賴于此接口了。所以我們將這個接口和基礎的Observable結合一下:
public interface Repository<T> extends Observable, Supplier<T> {}
這里的Repository<T>在一定程度上就是我們想要的RxJava中的Observable<T>啦。
類似地,Repository<T>也有兩種類型的實現:
- Direct - 所包含的數據總是可用的或者是可被同步計算出來的;一個Direct的
Repository總是處于活躍(active)狀態下 - Deferred - 所包含的數據是異步計算或拉去所得;一個Deffered的
Repository直到有Updatable被添加進來之前都會是非活躍(inactive)狀態下
是不是感到似曾相識呢?沒錯,Repository也是有冷熱區分的,不過我們現在暫且不去關注這一點。回到上面接著看,既然現在發數據的角色有了,那么我們要如何接收數據呢?答案就是Receiver:
/**
* A receiver of objects.
*/
public interface Receiver<T> {
/**
* Accepts the given {@code value}.
*/
void accept(@NonNull T value);
}
相信看到這里,大家應該也隱約感覺到了:在Agera的世界里,數據的傳輸與事件的傳遞是相互隔離開的,這是目前Agera與Rx系列的最大本質區別。Agera所使用的是一種push event, pull data的模型,這意味著event并不會攜帶任何data,Updatable在需要更新時,它自己會承擔起從數據源拉取數據的任務。這樣,提供數據的責任就從Observable中拆分了出來交給了Repository,讓其自身能夠專注于發送一些簡單的事件如按鈕點擊、一次下拉刷新的觸發等等。
那么,這樣的實現有什么好處呢?
當這兩種處理分發邏輯分離開時,Updatable就不必觀察到來自Repository的完整數據變化的歷史,畢竟在大多數場景下,尤其是更新UI的場景下,最新的數據往往才是有用的數據。
但是我就是需要看到變化的歷史數據,怎么辦?
不用擔心,這里我們再請出一個角色Reservoir:
public interface Reservoir<T> extends Receiver<T>, Repository<Result<T>> {}
顧名思義,Reservoir就是我們用來存儲變化中的數據的地方,它繼承了Receiver、Repository,也就相當于同時具有了接收數據,發送數據的能力。通過查看其具體實現我們可以知道它的本質操作都是使用內部的Queue實現的:通過accept()接收到數據后入列,通過get()拿到數據后出列。若一個Updatable觀察了此Reservoir,其隊列中發生調度變化后即將出列的下一個數據如果是可用的(非空),就會通知該Updatable,進一步拉取這個數據發送給Receiver。
(在Agera的Github的Sample中有一個有關Reservoir使用場景的例子:NotesStore.java,建議讀完全文后再來看此例)
現在,我們已經大概了解了這幾個角色的功能屬性了,接下來我們來看一段官方示例代碼:
public class AgeraActivity extends Activity
implements Receiver<Bitmap>, Updatable {
private static final ExecutorService NETWORK_EXECUTOR =
newSingleThreadExecutor();
private static final ExecutorService DECODE_EXECUTOR =
newSingleThreadExecutor();
private static final String BACKGROUND_BASE_URL =
"http://www.gravatar.com/avatar/4df6f4fe5976df17deeea19443d4429d?s=";
private Repository<Result<Bitmap>> background;
private ImageView backgroundView;
@Override
protected void onCreate(final Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
// Set the content view
setContentView(R.layout.activity_main);
// Find the background view
backgroundView = (ImageView) findViewById(R.id.background);
// Create a repository containing the result of a bitmap request. Initially
// absent, but configured to fetch the bitmap over the network based on
// display size.
background = Repositories.repositoryWithInitialValue(Result.<Bitmap>absent())
.observe() // Optionally refresh the bitmap on events. In this case never
.onUpdatesPerLoop() // Refresh per Looper thread loop. In this case never
.getFrom(new Supplier<HttpRequest>() {
@NonNull
@Override
public HttpRequest get() {
DisplayMetrics displayMetrics = getResources().getDisplayMetrics();
int size = Math.max(displayMetrics.heightPixels,
displayMetrics.widthPixels);
return httpGetRequest(BACKGROUND_BASE_URL + size)
.compile();
}
}) // Supply an HttpRequest based on the display size
.goTo(NETWORK_EXECUTOR) // Change execution to the network executor
.attemptTransform(httpFunction())
.orSkip() // Make the actual http request, skip on failure
.goTo(DECODE_EXECUTOR) // Change execution to the decode executor
.thenTransform(new Function<HttpResponse, Result<Bitmap>>() {
@NonNull
@Override
public Result<Bitmap> apply(@NonNull HttpResponse response) {
byte[] body = response.getBody();
return absentIfNull(decodeByteArray(body, 0, body.length));
}
}) // Decode the response to the result of a bitmap, absent on failure
.onDeactivation(SEND_INTERRUPT) // Interrupt thread on deactivation
.compile(); // Create the repository
}
@Override
protected void onResume() {
super.onResume();
// Start listening to the repository, triggering the flow
background.addUpdatable(this);
}
@Override
protected void onPause() {
super.onPause();
// Stop listening to the repository, deactivating it
background.removeUpdatable(this);
}
@Override
public void update() {
// Called as the repository is updated
// If containing a valid bitmap, send to accept below
background.get().ifSucceededSendTo(this);
}
@Override
public void accept(@NonNull Bitmap background) {
// Set the background bitmap to the background view
backgroundView.setImageBitmap(background);
}
}
是不是有些云里霧里的感覺呢?多虧有注釋,我們大概能夠猜出到底上面都做了什么:使用需要的圖片規格作為參數拼接到url中,拉取對應的圖片并用ImageView顯示出來。我們結合API來看看整個過程:
- Repositories.repositoryWithInitialValue(Result.<Bitmap>absent())
創建一個可運行(抑或說執行)的repository。
初始化傳入值是Result,它用來概括一些諸如apply()、merge()的操作的結果的不可變對象,并且存在兩種狀態succeeded()、failed()。
返回REventSource - observe()
用于添加新的Observable作為更新我們的圖片的Event source,本例中不需要。
返回RFrequency - onUpdatesPerLoop()
在每一個Looper Thread loop中若有來自多個Event Source的update()處理時,只需開啟一個數據處理流。
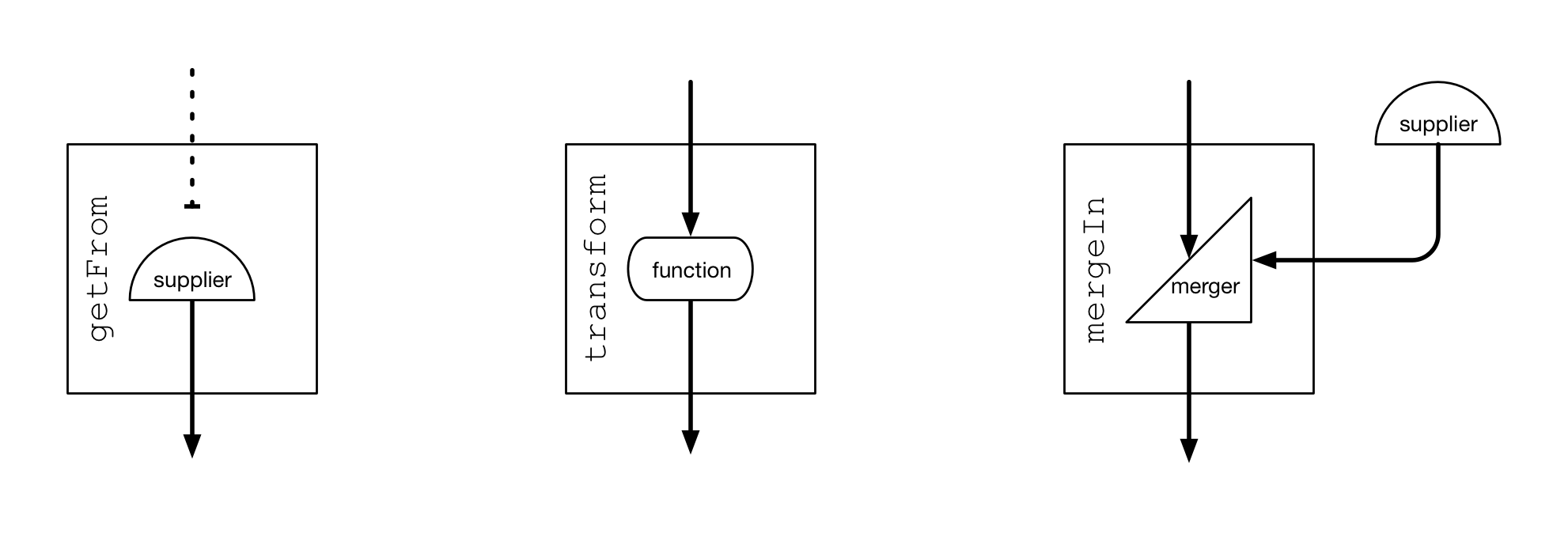
返回RFlow - getFrom(new Supplier(...))
忽略輸入值,使用來自給定Supplier的新獲取的數據作為輸出值。
返回RFlow - goTo(executor)
切換到給定的executor繼續數據處理流。 - attemptTransform(function())
使用給定的function()變換輸入值,若變換失敗,則終止數據流;若成功,則取新的變換后的值作為當前流指令的輸出。
返回RTermination - orSkip()
若前面的操作檢查為失敗,就跳過剩下的數據處理流,并且不會通知所有已添加的Updatable。 - thenTransform(function())
與attemptTransform(function())相似,區別在于當必要時會發出通知。
返回RConfig - onDeactivation(SEND_INTERRUPT)
用于明確repository不再active時的行為。
返回RConfig - compile()
執行這個repository。
返回Repository
整體流程乍看起來并沒有什么特別的地方,但是真正的玄機其實藏在執行每一步的返回值里:
初始的REventSource<T, T>代表著事件源的開端,它從傳入值接收了T initialValue,這里的<T, T>中,第一個T是當前repository的數據的類型,第二個T則是數據處理流開端的時候的數據的類型。
之后,當observe()調用后,我們傳入事件源給REventSource,相當于設定好了需要的事件源和對應的開端,這里返回的是RFrequency<T, T>,它繼承自REventSource,為其添加了事件源的發送頻率的屬性。
之后,我們來到了onUpdatesPerLoop(),這里明確了所開啟的數據流的個數(也就是前面所講的頻率)后,返回了RFlow,這里也就意味著我們的數據流正式生成了。同時,這里也是流式調用的起點。
拿到我們的RFlow之后,我們就可以為其提供數據源了,也就是前面說的Supplier,于是調用getFrom(),這樣我們的數據流也就真正意義擁有了數據“干貨”。
有了數據之后我們就可以按具體需要進行數據轉換了,這里我們可以直接使用transform(),返回RFlow,以便進一步進行流式調用;也可以調用attemptTransform()來對可能出現的異常進行處理,比如orSkip()、orEnd()之后繼續進行流式調用。
經過一系列的流式調用之后,我們終于對數據處理完成啦,現在我們可以選擇先對成型的數據在做一次最后的包裝thenTransform(),或是與另一個Supplier合并thenMergeIn()等。這些處理之后,我們的返回值也就轉為了RConfig,進入了最終配置和repository聲明結束的狀態。
在最終的這個配置過程中,我們調用了onDeactivation(),為這個repository明確了最終進入非活躍狀態時的行為,如果不需要其他多余的配置的話,我們就可以進入最終的compile()方法了。當我們調用compile()時,就會按照前面所走過的所有流程與配置去執行并生成這個repository。到此,我們的repository才真正被創建了出來。
以上就是repository從無到有的全過程。當repository誕生后,我們也就可以傳輸需要的數據啦。再回到上面的示例代碼:
@Override
protected void onResume() {
super.onResume();
// Start listening to the repository, triggering the flow
background.addUpdatable(this);
}
@Override
protected void onPause() {
super.onPause();
// Stop listening to the repository, deactivating it
background.removeUpdatable(this);
}
我們在onResume()、onPause()這兩個生命周期下分別添加、移除了Updatable。相較于RxJava中通過Subscription去取消訂閱的做法,Agera的這種寫法顯然更為清晰也更為整潔。
我們的Activity實現了Updatable和Receiver接口,直接看其實現方法:
@Override
public void update() {
// Called as the repository is updated
// If containing a valid bitmap, send to accept below
background.get().ifSucceededSendTo(this);
}
@Override
public void accept(@NonNull Bitmap background) {
// Set the background bitmap to the background view
backgroundView.setImageBitmap(background);
}
可以看到這里repository將數據發送給了receiver,也就是自己,在對應的accept()方法中接收到我們想要的bitmap后,這張圖片也就顯示出來了,示例代碼中的完整流程也就結束了。
總結一下上述過程:

- 首先
Repositories.repositoryWithInitialValue()生成原點REventSource。 - 配置完
Observable之后進入RFrequency狀態,接著配置數據流的流數。 - 前面配置完成后,數據流
RFlow生成,之后通過getFrom()、mergeIn()、transform()等方法可進一步進行流式調用;也可以使用attemptXXX()方法代替原方法,后面接著調用orSkip()、orEnd()進行error handling處理。當使用attemptXXX()方法時,數據流狀態會變為RTermination,它代表此時的狀態已具有終結數據流的能力,是否終結數據流要根據failed check觸發,結合后面跟著調用的orSkip()、orEnd(),我們的數據流會從RTermination再次切換為RFlow,以便進行后面的流式調用。
- 經過前面一系列的流式處理,我們需要結束數據流時,可以選擇調用
thenXXX()方法,對數據流進行最終的處理,處理之后,數據流狀態會變為RConfig;也可以為此行為添加error handling處理,選擇thenAttemptXXX()方法,后面同樣接上orSkip()、orEnd()即可,最終數據流也會轉為Rconfig狀態。 - 此時,我們可以在結束前按需要選擇對數據流進行最后的配置,例如:調用
onDeactivation()配置從“訂閱”到“取消訂閱”的過程是否需要繼續執行數據流等等。 - 一切都部署完畢后,我們
compile()這個RConfig,得到最終的成型的Repository,它具有添加Updatable、發送數據通知Receiver的能力。 - 我們根據需要添加
Updatable,repository在數據流處理完成后會通過update()發送event通知Updatable。 -
Updatable收到通知后則會拉取repository的成果數據,并將數據通過accept()發送給Receiver。完成 Push event, pull data 的流程。
以上就是一次Agera的流式調用的內部基本流程。可以看到,除了 Push event, pull data 這一特點、goLazy的加載模式(本文未介紹)等,依托于較為精簡的方法,Agera的流式調用過程同樣也能夠做到過程清晰,并且上手難度相較于RxJava也要簡單一些,開源作者是Google的團隊也讓一些G粉對其好感度提升不少。不過Agera目前版本則是 agera-1.0.0-rc2,未來的版本還有很多不確定因素,相比之下Rx系列發展了這么久,框架已經相對成熟。究竟用Agera還是RxJava,大家按自己的喜好選擇吧。
新人處女作,文章中難免會有錯誤遺漏以及表述不清晰的地方,希望大家多多批評指正,謝謝!
參考&拓展:
RxJava Wiki
Agera Wiki
給 Android 開發者的 RxJava 詳解
Google Agera vs. ReactiveX
When Iron Man becomes reactive
Top 7 Tips for RxJava on Android
How to Keep your RxJava Subscribers from Leaking
RxJava – the production line
