本系列文章記錄學習的過程。
0. 前言
由于課程授課和課件(Lecture Slides)均為英文,所以文中許多專有名詞會標注英文,中文翻譯參考《Algorithms Fourth Edition》中文版。課件以及其它資料下載鏈接會在文末給出。
1. 動態連通性(Dynamic Connectivity)
1.1 定義
什么是動態連通性?
Given a set of N objects.
?Union command: connect two objects.
?Find/connected query: is there a path connecting the two objects?
給定幾個數的集合
- Union操作: 在兩個數之間加一條連接。
- Find/connected查詢: 判斷兩個數之間是否有連接。
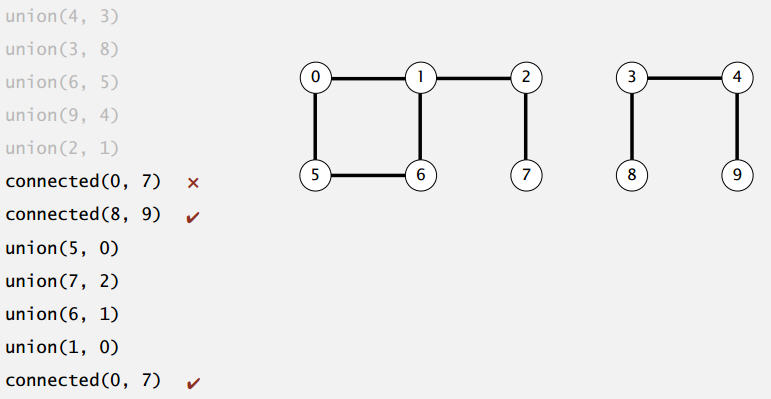
1.2 建立模型
如何選擇具體的數據結構模型呢?
動態連通性的應用十分廣泛:
- 照片的像素
- 網絡中的電腦
- 社交網絡中的兩個人
- 電路芯片中的晶體管
- 數學集合中的元素
...
比較容易實現的選擇:使用數組,讓數組的每個下標代表每個數。
我們繼續假設: “相連(is connected to)” 是兩個數之間的一種關系,且這種關系滿足以下條件:
- 自反性(Reflexive): p和p是相連的;
- 對稱性(Symmetric): 如果p和q是相連的,那么q和p也是相連的;
- 傳遞性(Transitive): 如果p和q相連且q和r相連,那么p和r相連。
當兩個數相連時,它們屬于同一個等價類(Connected Components)。
等價類,就是所有相連的數的集合,這個集合必須包含所有相連的數。
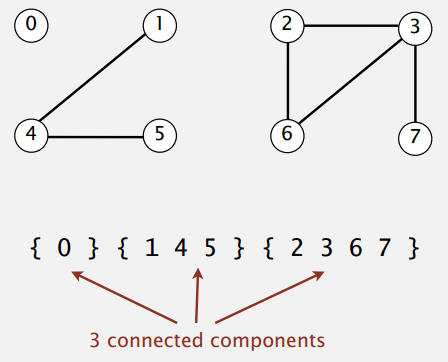
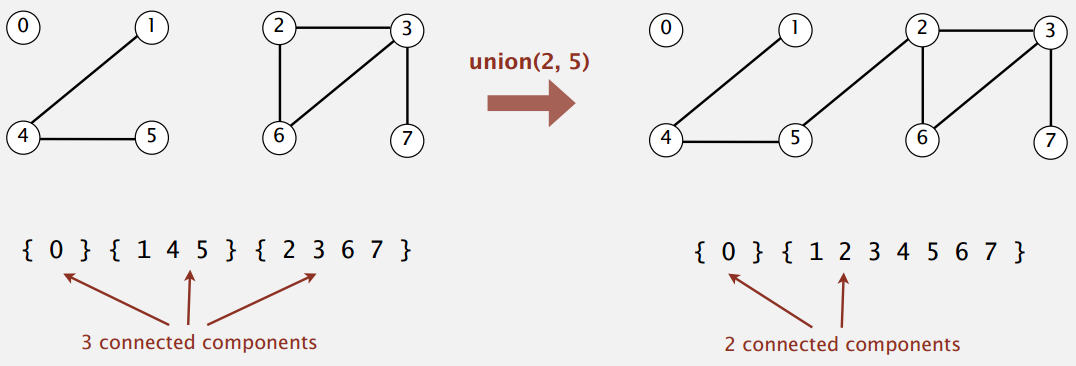
具體的操作,給定兩個數:
- Find操作: 查看兩個數是否屬于同一個等價類。
- Union操作: 將兩個數連接起來,這個操作其實就是將兩個數所在的等價類聯合成一個等價類。
在這里約定一下使用的術語:
| 英文 | 漢語術語 |
|---|---|
| Connected Components | 等價類 / 分量 |
| node | 節點 |
1.3 Union-Find數據類型(Union-Find data type)
由1.2 我們得出了簡單的數據模型,現在需要設計具體的數據類型,我們的目標是:
- 為Union-Find操作設計出一個高效的數據類型
- 每個數據類型包含N個數,N可能會很大
- 操作的次數M可能很大
- Find操作和Union操作可能會交叉進行
以下是API:
| public class UF | |
|---|---|
| UF(int N) | 用整數N(0到N-1)初始化N個點 |
| void union(int p, int q) | 為點p和點q之間添加一條連接 |
| boolean connected(int p, int q) | 判斷點p和點q是否屬于同一個分量 |
| int find(int p) | p所在分量的標識符(0到N-1) |
| int count() | 分量的數量 |
2. Quick Find算法
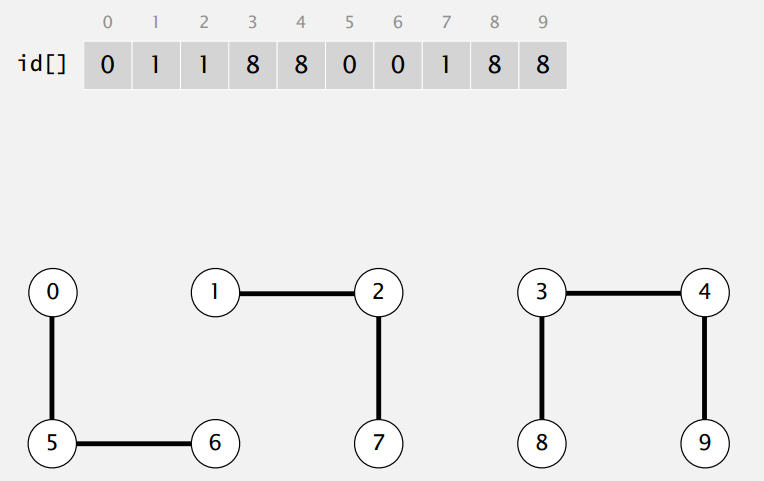
2.1 數據結構
- 整數型數組id[],長度為N。
- p和q是相連的等價于數組中p下標和q下標的數相同。
2.2 Java實現

2.3 算法分析
QuickFind算法太慢了。
下表是最壞情況下QuickFind算法對一組點操作使用的時間消耗。
| 算法 | 初始化 | union操作 | find操作 |
|---|---|---|---|
| QuickFind | N | N | 1 |
Union操作過于緩慢:如果要對N對點進行union操作,最多需要對數組訪問N^2次。
3. Quick Union算法
3.1 數據結構
- 整數型數組id[],長度為N。
- id[i]中存儲i的父節點( 也就是形成一個鏈接,直到其父節點就是它自己,說明到頭了)
- i的根節點(root)是id[id[id[id[...id[i]...]]]]
具體操作:
- Find操作:檢查p和q是否擁有同一個根節點 。
-
Union操作: 為了合并p和q各自所在的分量,將p的根節點改為q的根節點。
 QuickUnion
QuickUnion
3.2 Java實現

3.3 算法分析
對一對點進行操作需要訪問數組的次數,圖中是最壞情況。
| 算法 | 初始化 | union操作 | find操作 |
|---|---|---|---|
| QuickFind | N | N | 1 |
| QuickUnion | N | N* | N |
*:包括了尋找根節點的操作。
QuickFind的缺點
- Union操作太慢了,最差為N
- 樹是平的,但是維護這個狀態時間耗費太大了
QuickUnion的缺點
- 樹可能會很高
- Find操作太慢了,最差為N
4. 改進1 - 加權(weighting)
4.1 數據結構
加權QuickUnion(Weighted QuickUnion)
- 改進QuickUnion,避免太高的樹
- 對每個樹的大小(包含點的數量)進行記錄
- union操作時,比較兩個點所在樹的大小,小數的根節點連接到大樹的根節點之上

數據結構其實和QuickUnion相同,但是需要再維護一個額外的數組sz[i],用來記錄以i節點為根節點的分量的大小(及分量中數的多少)
4.2 Java實現
Find操作:和QuickUnion相同
return root(p) == root(q);
Union操作:改進的QuickUnion
- 將較小的樹的根節點連接到大的樹的根節點上
- 不斷更新sz[]數組
int i = root(p);
int j = root (q);
if(i == j) return;
if(sz[i] < sz[j]) { id[i] = j; sz[j] += sz[i];}
else { id[j] = i; sz[i] += sz[j];}
4.3 算法分析
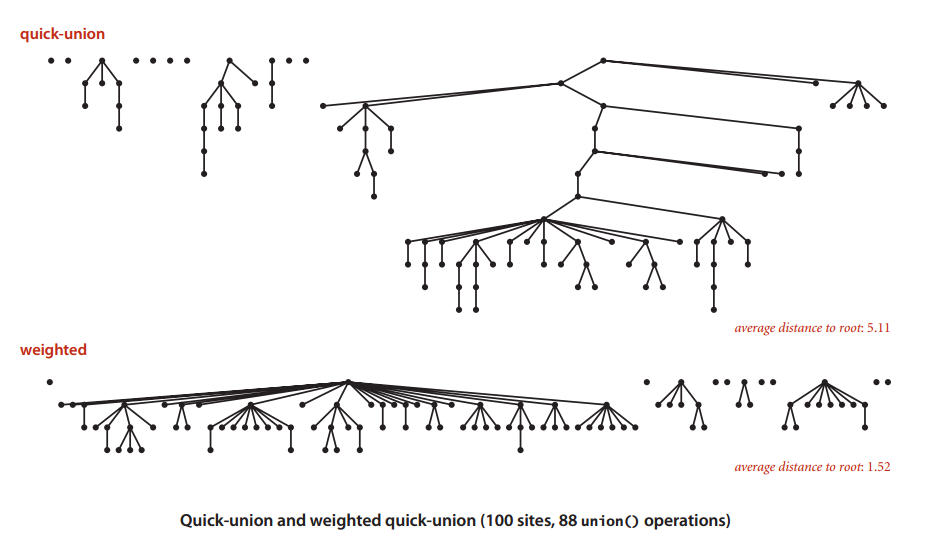
運行時間
- Find操作: 時間和p以及q的深度成正比
- Union操作: 給定根節點,時間為常數
命題: 任意節點x,其深度最大為lg N 。
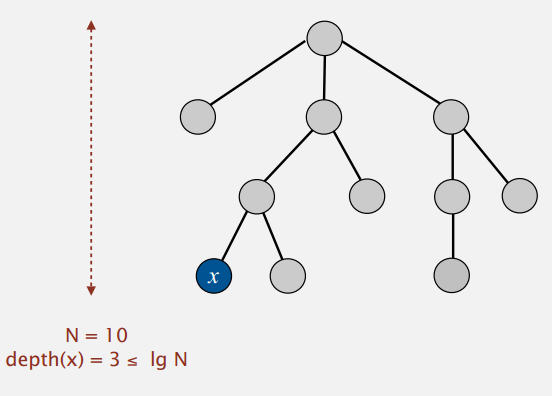
證明:
什么時候x的深度會增大呢?
當樹T2比樹T1大,即|T2| >= |T1|時,包含x的樹T1成為另一個樹T2的子樹時,x的深度會加1。由此推出:
- T1和T2合起來的新樹,其大小至少是之前T1的2倍。(也就是x所在的樹大小增大1倍,x的深度加1)
-
包含x的樹最多可以翻倍lg N 次。
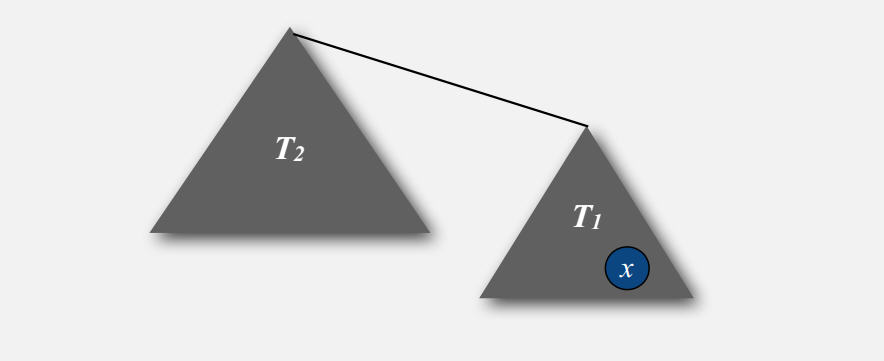 WeightedQuickUnionAnalysis
WeightedQuickUnionAnalysis
算法分析
| 算法 | 初始化 | union操作 | find操作 |
|---|---|---|---|
| QuickFind | N | N | 1 |
| QuickUnion | N | N* | N |
| weighted QU | N | (lg N)* | lg N |
*:包括了尋找根節點的操作。
還可以優化嗎?答案是肯定的。
5. 改進2 - 路徑壓縮(Path Compression)
5.1 數據結構
在計算點p的根節點root之后,每個經過的節點,如果其根節點不為root的話,讓其根節點變成root,如圖是帶路徑壓縮的QuickUnion算法(Quick Union with Path Compression),下圖是具體的過程。

5.2 Java實現
private int root(int i) {
int temp; // 臨時節點
while(i != id[i]) {
temp = id[i]; // 用臨時節點記錄i節點的父節點
id[i] = find(i);// 將i節點的父節點置為根節點
i = temp; // 對i節點之前的父節點進行重復性判斷
}
return i;
}
5.3 算法分析
使用帶路徑壓縮的加權Quick Union算法,對于N個數,M次操作時,訪問數組次數最多為c (N + M lg* N)。
(c為常數, lg* N是lg(lg(lg(...lg()...)))。)
對于N個數,M次操作時,有沒有線性訪問數組次數的算法呢?
- 理論上, WQUPC(Weighted Quick Union & Path Compression)不是線性的
- 實際中,WQUPC基本是線性的
現已證明,沒有完全的線性算法存在。
6. 總結
使用帶路徑壓縮的加權Quick Union算法,使得之前不可能被解決的問題現在可以被解決。

對于109次union操作和109次find操作:
- WQUPC讓時間從30年變成了6s
- 超級計算機并不能幫助太多,但是好的算法可以讓問題得到充分解決
7. 參考網址
[1] 課程首頁(Course Page)
[2] Algorithms 4th
[3] 課件下載(Lecture Slides)
