這是我在 The Bioinformatics Knowledgeblog 上看到的一篇教程,原文在這里,教程條理清晰,對我理解芯片數據分析流程幫助很大,就把它翻譯了過來。
介紹
芯片數據分析流程有些復雜,但使用 R 和 Bioconductor 包進行分析就簡單多了。本教程將一步一步的展示如何安裝 R 和 Bioconductor,通過 GEO 數據庫下載芯片數據, 對數據進行標準化,然后對數據進行質控檢查,最后查找差異表達的基因。教程示例安裝的各種依賴包和運行命令均是是在 Ubuntu 環境中運行的(版本: Ubuntu 10.04, R 2.121),教程的示例代碼和圖片在這里。
安裝 R 和 Bioconductor 包
打開命令終端,先安裝 R 和 Bioconductor 的依賴包,然后安裝 R.
$ sudo apt-get install r-base-core libxml2-dev libcurl4-openssl-dev curl
$ R
之后在 R 環境中安裝 Bioconductor 包
> # 下載 Bioconductor 的安裝程序
> source("http://bioconductor.org/biocLite.R")
> # 安裝 Bioconductor 的核心包
> biocLite()
> # 安裝 GEO 包
> biocLite("GEOquery")
如果你沒有管理員權限,你需要將這些包安裝到你個人庫目錄中。安裝 Bioconductor 需要一段時間,GEOquery 包也需要安裝,GEOquery 是 NCBI 存儲標準化的轉錄組數據的基因表達綜合數據庫 GEO 的接口程序。
下載芯片數據
本教程中我們使用 Dr Andrew Browning 發表的數據集 GSE20986。HUVECs(人臍靜脈內皮細胞)是從人胎兒臍帶血中提取出來的,通常用來研究內皮細胞的病理生理機制。這個實驗設計中,從捐獻者的眼組織中提取的虹膜、視網膜、脈絡膜微血管內皮細胞用來和 HUVEC 細胞進行比對,以便考查 HUVEC 細胞能否替代其他細胞作為研究眼科疾病的樣本。 GEO 頁面同時也包含了關于本實驗研究的其他信息。對于每組樣本有三次測量,樣品分成四組 iris, retina, HUVEC, choroidal 。
實驗平臺是 GPL570 -- GEO 數據庫對人類轉錄組芯片 Affymetrix Human Genome U133 Plus 2.0 Array 的縮寫。通過 GSM 鏈接 GSM524662,我們可以得到各個芯片的更多實驗條件信息。同一個實驗設計中的不同芯片的實驗條件應該是相同的。不同細胞系的提取條件,細胞生長條件,RNA 提取程序,RNA 處理程序,RNA 與探針雜交條件,用哪種儀器掃描芯片,這些數據都以符合 MIAME 標準的形式存儲著。
對于每一個芯片,數據表中存儲著探針組和對應探針組標準化之后的基因表達量值。表頭中提供了表達量值標準化所用的算法。本教程中使用 GC-RMA 算法進行數據標準化,關于 GC-RMA 算法的詳細細節可以參考這篇文獻。
首先,我們從 GEO 數據庫下載原始數據,導入 GEOquery 包,用它下載原始數據,下載的原始數據約 53MB。
> library(GEOquery)
> getGEOSuppFiles("GSE20986")
下載完成后,打開文件管理器,在啟動 R 程序的文件夾里可以看到當前文件夾下生成了一個 GSE20986 文件夾,可以直接查看文件夾里的內容:
$ ls GSE20986/
filelist.txt GSE20986_RAW.tar
GSE20986_RAW.tar 文件是壓縮打包的 CEL(Affymetrix array 數據原始格式)文件。先解包數據,再解壓數據。這些操作可以直接在 R 命令終端中進行:
> untar("GSE20986/GSE20986_RAW.tar", exdir="data")
> cels <- list.files("data/", pattern = "[gz]")
> sapply(paste("data", cels, sep="/"), gunzip)
> cels
芯片實驗信息整理
在對數據進行分析之前,我們需要先整理好實驗設計信息。這其實就是一個文本文件,包含芯片名字、此芯片上雜交的樣本名字。為了方便在 R 中 使用 simpleaffy 包讀取實驗信息文本文件,需要先編輯好格式:
$ ls -1 data/*.CEL > data/phenodata.txt
將這個文本文件用編輯器打開,現在其中只有一列 CEL 文件名,最終的實驗信息文本需要包含三列數據(用 tab 分隔),分別是 Name, FileName, Target。本教程中 Name 和 FileName 這兩欄是相同的,當然 Name 這一欄可以用更加容易理解的名字代替。
Target 這一欄數據是芯片上的樣本標簽,例如 iris, retina, HUVEC, choroidal,這些標簽定義了那些數據是生物學重復以便后面的分析。
這個實驗信息文本文件最終格式是這樣的:
Name FileName Target
GSM524662.CEL GSM524662.CEL iris
GSM524663.CEL GSM524663.CEL retina
GSM524664.CEL GSM524664.CEL retina
GSM524665.CEL GSM524665.CEL iris
GSM524666.CEL GSM524666.CEL retina
GSM524667.CEL GSM524667.CEL iris
GSM524668.CEL GSM524668.CEL choroid
GSM524669.CEL GSM524669.CEL choroid
GSM524670.CEL GSM524670.CEL choroid
GSM524671.CEL GSM524671.CEL huvec
GSM524672.CEL GSM524672.CEL huvec
GSM524673.CEL GSM524673.CEL huvec
注意:每欄之間是使用 Tab 進行分隔的,而不是空格!
載入數據并對其進行標準化
需要先安裝 simpleaffy 包,simpleaffy 包提供了處理 CEL 數據的程序,可以對 CEL 數據進行標準化同時導入實驗信息(即前一步中整理好的實驗信息文本文件內容),導入數據到 R 變量 celfiles 中:
> biocLite("simpleaffy")
> library(simpleaffy)
> celfiles <- read.affy(covdesc="phenodata.txt", path="data")
你可以通過輸入 ‘celfiles’ 來確定數據導入成功并添加芯片注釋(第一次輸入 ‘celfiles’ 的時候會進行注釋):
> celfiles
AffyBatch object
size of arrays=1164x1164 features (12 kb)
cdf=HG-U133_Plus_2 (54675 affyids)
number of samples=12
number of genes=54675
annotation=hgu133plus2
notes=
現在我們需要對數據進行標準化,使用 GC-RMA 算法對 GEO 數據庫中的數據進行標準化,第一次運行的時候需要下載一些其他的必要文件:
> celfiles.gcrma <- gcrma(celfiles)
Adjusting for optical effect............Done.
Computing affinitiesLoading required package: AnnotationDbi
.Done.
Adjusting for non-specific binding............Done.
Normalizing
Calculating Expression
如果你想看標準化之后的數據,輸入 celfiles.gcrma, 你會發現提示已經不是 AffyBatch object 了,而是 ExpressionSet object,是已經標準化了的數據:
> celfiles.gcrma
ExpressionSet (storageMode: lockedEnvironment)
assayData: 54675 features, 12 samples
element names: exprs
protocolData
sampleNames: GSM524662.CEL GSM524663.CEL ... GSM524673.CEL (12 total)
varLabels: ScanDate
varMetadata: labelDescription
phenoData
sampleNames: GSM524662.CEL GSM524663.CEL ... GSM524673.CEL (12 total)
varLabels: sample FileName Target
varMetadata: labelDescription
featureData: none
experimentData: use 'experimentData(object)'
Annotation: hgu133plus2
數據質量控制
再進行下一步的數據分析之前,我們有必要對數據質量進行檢查,確保沒有其他的問題。首先,可以通過對標準化之前和之后的數據畫箱線圖來檢查 GC-RMA 標準化的效果:
> # 載入色彩包
> library(RColorBrewer)
> # 設置調色板
> cols <- brewer.pal(8, "Set1")
> # 對標準化之前的探針信號強度做箱線圖
> boxplot(celfiles, col=cols)
> # 對標準化之后的探針信號強度做箱線圖,需要先安裝 affyPLM 包,以便解析 celfiles.gcrma 數據
> biocLite("affyPLM")
> library(affyPLM)
> boxplot(celfiles.gcrma, col=cols)
> # 標準化前后的箱線圖會有些變化
> # 但是密度曲線圖看起來更直觀一些
> # 對標準化之前的數據做密度曲線圖
> hist(celfiles, col=cols)
> # 對標準化之后的數據做密度曲線圖
> hist(celfiles.gcrma, col=cols)
數據標準化之前的箱線圖
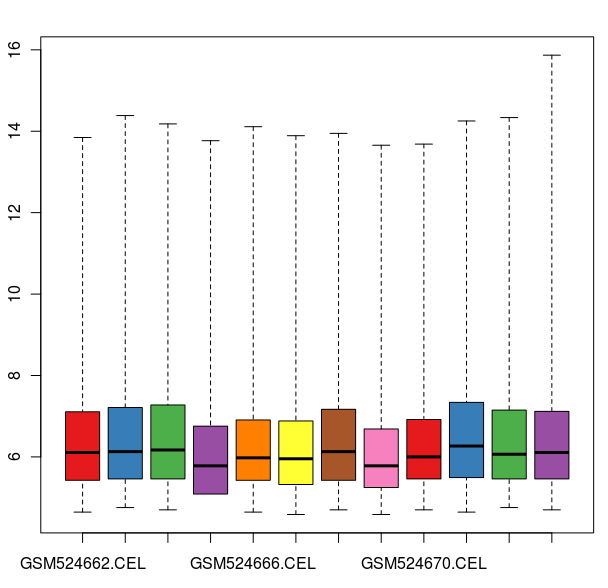
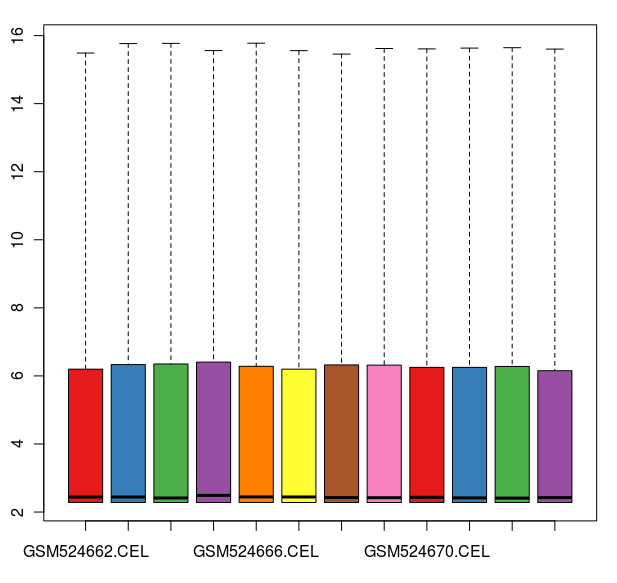
數據標準化之后的箱線圖
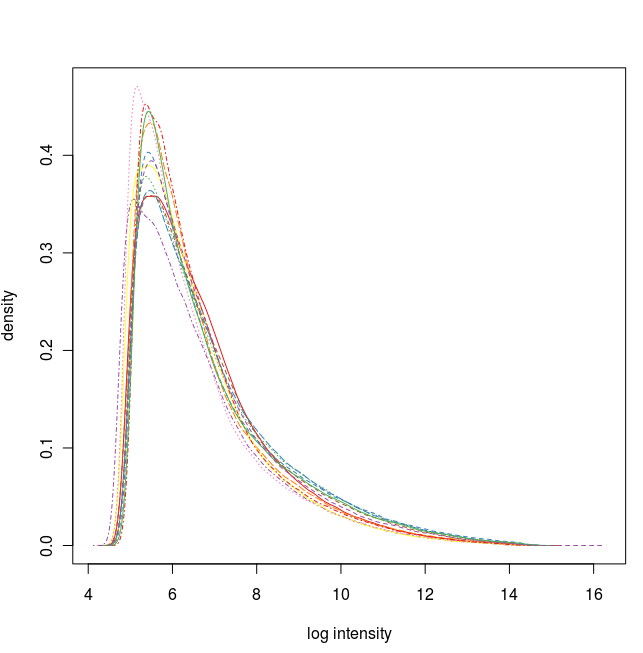
數據標準化之前的密度曲線圖
數據標準化之后的密度曲線圖
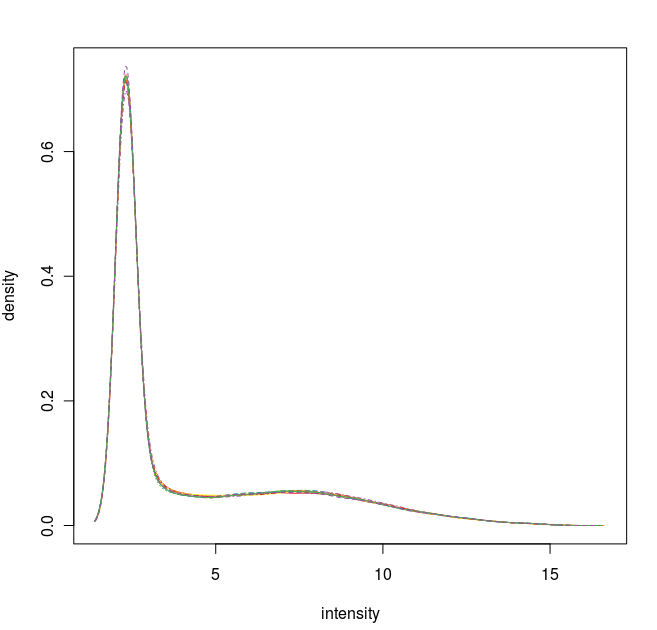
通過這些圖我們可以看出這12張芯片數據之間差異不大,標準化處理將所有芯片信號強度標準化到具有類似分布特征的區間內。為了更詳細地了解芯片探針信號強度,我們可以使用 affyPLM 對單個芯片 CEL 數據進行可視化。
> # 從 CEL 文件讀取探針信號強度:
> celfiles.qc <- fitPLM(celfiles)
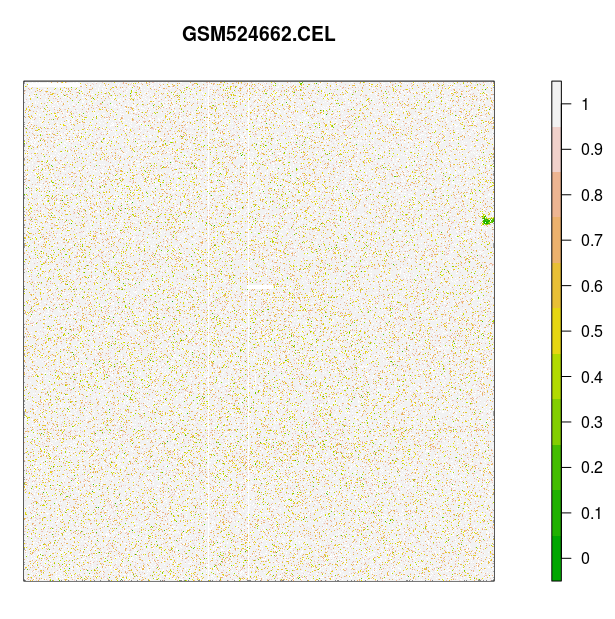
> # 對芯片 GSM24662.CEL 信號進行可視化:
> image(celfiles.qc, which=1, add.legend=TRUE)
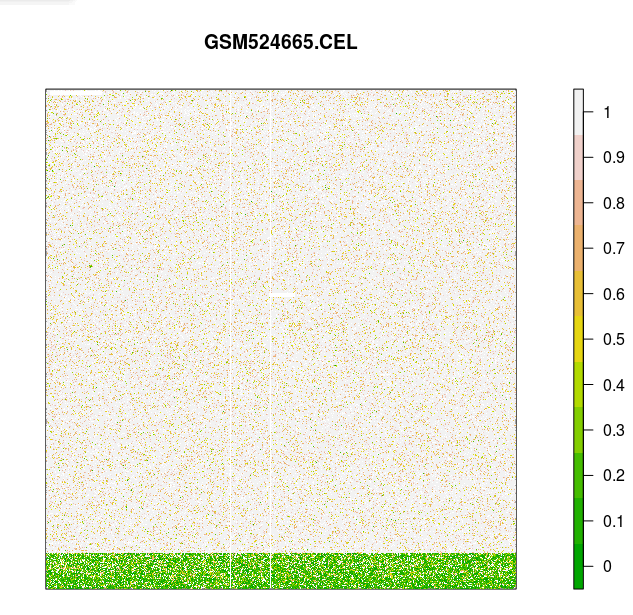
> # 對芯片 GSM524665.CEL 進行可視化
> # 這張芯片數據有些人為誤差
> image(celfiles.qc, which=4, add.legend=TRUE)
> # affyPLM 包還可以畫箱線圖
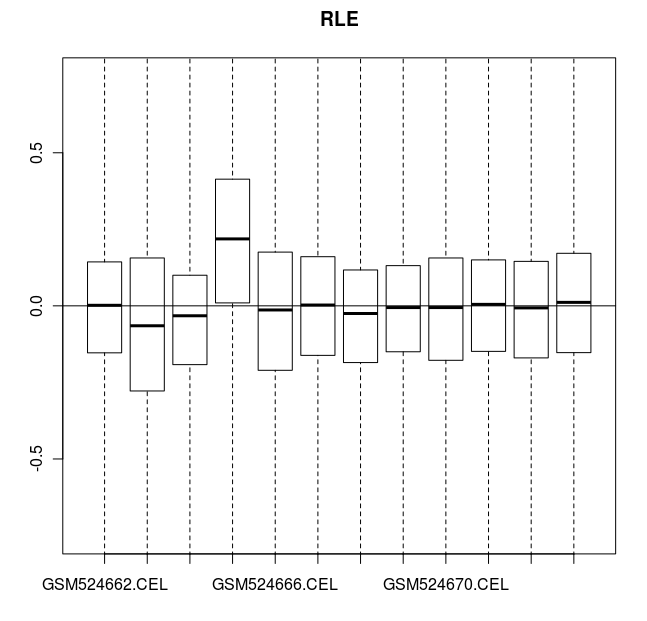
> # RLE (Relative Log Expression 相對表達量取對數) 圖中
> # 所有的值都應該接近于零。 GSM524665.CEL 芯片數據由于有人為誤差而例外。
> RLE(celfiles.qc, main="RLE")
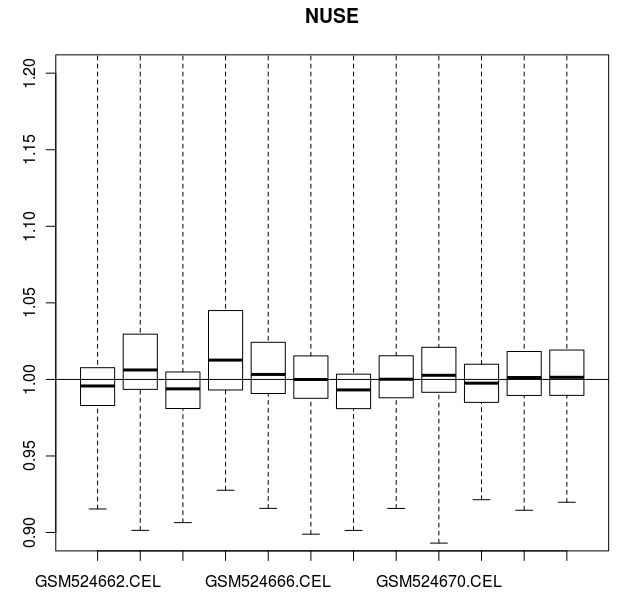
> # 也可以用 NUSE (Normalised Unscaled Standard Errors)作圖比較.
> # 對于絕大部分基因,標準差的中位數應該是1。
> # 芯片 GSM524665.CEL 在這個圖中,同樣是一個例外
> NUSE(celfiles.qc, main="NUSE")
標準的芯片 AffyPLM 信號圖
存在人工誤差的芯片 AffyPLM 信號圖
CEL 數據的 RLE 圖
CEL 數據的 NUSE 圖
我們還可以通過層次聚類來查看樣本之間的關系:
> eset <- exprs(celfiles.gcrma)
> distance <- dist(t(eset),method="maximum")
> clusters <- hclust(distance)
> plot(clusters)
CEL 數據的層次聚類圖
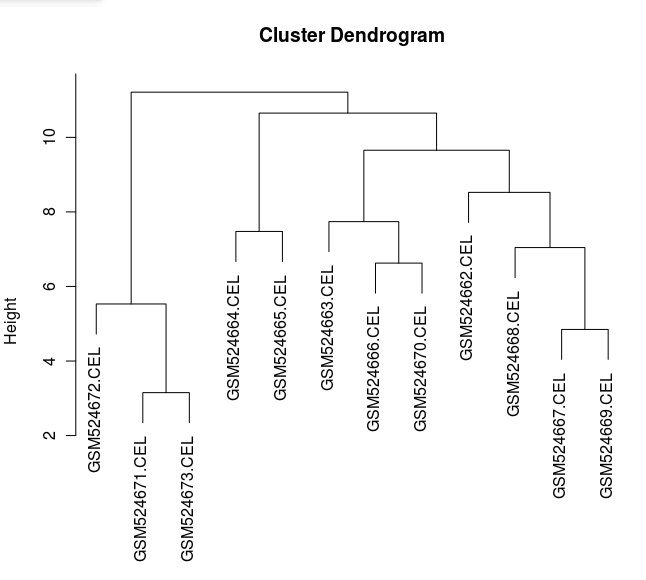
圖形顯示,與其他眼組織相比 HUVEC 樣品是單獨的一組,表現出組織類型聚集的一些特征,另外 GSM524665.CEL 數據在此圖中并不顯示為異常值。
數據過濾
現在我們可以對數據進行分析了,分析的第一步就是要過濾掉數據中的無用數據,例如作為內參的探針數據,基因表達無明顯變化的數據(在差異表達統計時也會被過濾掉),信號值與背景信號差不多的探針數據。
下面的 nsFilter 參數是為了不刪除沒有 Entrez Gene ID 的位點,保留有重復 Entrez Gene ID 的位點:
> celfiles.filtered <- nsFilter(celfiles.gcrma, require.entrez=FALSE, remove.dupEntrez=FALSE)
> # 哪些位點被過濾掉了?為什么?
> celfiles.filtered$filter.log
$numLowVar
[1] 27307
$feature.exclude
[1] 62
我們可以看出有 27307 個探針位點因為無明顯表達差異(LowVar)被過濾掉,有 62 個探針位點因為是內參而被過濾掉。
查找有表達差異的探針位點
現在有了過濾之后的數據,我們就可以用 limma 包進行差異表達分析了。首先,我們要提取樣本的信息:
> samples <- celfiles.gcrma$Target
> # 檢查數據的分組信息
> samples
[1] "iris" "retina" "retina" "iris" "retina" "iris" "choroid"
[8] "choroid" "choroid" "huvec" "huvec" "huvec"
> # 將分組數據轉換為因子類型變量
> samples <- as.factor(samples)
> # 檢查轉換的因子變量
> samples
[1] iris retina retina iris retina iris choroid choroid choroid
[10] huvec huvec huvec
Levels: choroid huvec iris retina
> # 設置實驗分組
> design <- model.matrix(~0 + samples)
> colnames(design) <- c("choroid", "huvec", "iris", "retina")
> # 檢查實驗分組
> design
choroid huvec iris retina
1 0 0 1 0
2 0 0 0 1
3 0 0 0 1
4 0 0 1 0
5 0 0 0 1
6 0 0 1 0
7 1 0 0 0
8 1 0 0 0
9 1 0 0 0
10 0 1 0 0
11 0 1 0 0
12 0 1 0 0
attr(,"assign")
[1] 1 1 1 1
attr(,"contrasts")
attr(,"contrasts")$samples
[1] "contr.treatment"
現在我們將芯片數據進行了標準化和過濾,也有樣品分組和實驗分組信息,可以將數據導入 limma 包進行差異表達分析了:
> library(limma)
> # 將線性模型擬合到過濾之后的表達數據集上
> fit <- lmFit(exprs(celfiles.filtered$eset), design)
> # 建立對比矩陣以比較組織和細胞系
> contrast.matrix <- makeContrasts(huvec_choroid = huvec - choroid, huvec_retina = huvec - retina, huvec_iris <- huvec - iris, levels=design)
> # 檢查對比矩陣
> contrast.matrix
Contrasts
Levels huvec_choroid huvec_retina huvec_iris
choroid -1 0 0
huvec 1 1 1
iris 0 0 -1
retina 0 -1 0
> # 現在將對比矩陣與線性模型擬合,比較不同細胞系的表達數據
> huvec_fits <- contrasts.fit(fit, contrast.matrix)
> # 使用經驗貝葉斯算法計算差異表達基因的顯著性
> huvec_ebFit <- eBayes(huvec_fits)
> # 返回對應比對矩陣 top 10 的結果
> # coef=1 是 huvec_choroid 比對矩陣, coef=2 是 huvec_retina 比對矩陣
> topTable(huvec_ebFit, number=10, coef=1)
ID logFC AveExpr t P.Value adj.P.Val
6147 204779_s_at 7.367947 4.171874 72.77016 3.290669e-15 8.985500e-11
7292 207016_s_at 6.934796 4.027229 57.37259 3.712060e-14 5.068076e-10
8741 209631_s_at 5.193313 4.003541 51.22423 1.177337e-13 1.071612e-09
26309 242809_at 6.433514 4.167462 48.52518 2.042404e-13 1.394247e-09
6828 205893_at 4.480463 3.544350 40.59376 1.253534e-12 6.845801e-09
20232 227377_at 3.670688 3.209217 36.03427 4.200854e-12 1.911809e-08
6222 204882_at -5.351976 6.512018 -34.70239 6.154318e-12 2.400711e-08
27051 38149_at -5.051906 6.482418 -31.44098 1.672263e-11 5.282592e-08
6663 205576_at 6.586372 4.139236 31.31584 1.741131e-11 5.282592e-08
6589 205453_at 3.623706 3.210306 30.72793 2.109110e-11 5.759136e-08
B
6147 20.25563
7292 19.44681
8741 18.96282
26309 18.70767
6828 17.75331
20232 17.01960
6222 16.77196
27051 16.08854
6663 16.05990
6589 15.92277
分析結果的各列數據含義:
- 第一列是探針組在表達矩陣中的行號;
- 第二列“ID” 是探針組的 AffymatrixID;
- 第三列“logFC”是兩組表達值之間以2為底對數化的的變化倍數(Fold change, FC),由于基因表達矩陣本身已經取了對數,這里實際上只是兩組基因表達值均值之差;
- 第四列“AveExpr”是該探針組所在所有樣品中的平均表達值;
- 第五列“t”是貝葉斯調整后的兩組表達值間 T 檢驗中的 t 值;
- 第六列“P.Value”是貝葉斯檢驗得到的 P 值;
- 第七列“adj.P.Val”是調整后的 P 值;
- 第八列“B”是經驗貝葉斯得到的標準差的對數化值。
如果要設置一個倍數變化閾值,并查看不同閾值返回了多少基因,可以使用 topTable 的 lfc 參數,參數設置為 5,4,3,2 時返回的基因個數:
> nrow(topTable(huvec_ebFit, coef=1, number=10000, lfc=5))
[1] 88
> nrow(topTable(huvec_ebFit, coef=1, number=10000, lfc=4))
[1] 194
> nrow(topTable(huvec_ebFit, coef=1, number=10000, lfc=3))
[1] 386
> nrow(topTable(huvec_ebFit, coef=1, number=10000, lfc=2))
[1] 1016
> # 提取表達量倍數變化超過 4 的探針列表
> probeset.list <- topTable(huvec_ebFit, coef=1, number=10000, lfc=4)
注釋差異分析結果的基因 ID
為了將探針集注釋上基因 ID 我們需要先安裝一些數據庫的包和注釋的包,之后可以提取 topTable 中的探針 ID 并注釋上基因 ID:
> biocLite("hgu133plus2.db")
> library(hgu133plus2.db)
> library(annotate)
> gene.symbols <- getSYMBOL(probeset.list$ID, "hgu133plus2")
> results <- cbind(probeset.list, gene.symbols)
> head(results)
ID logFC AveExpr t P.Value adj.P.Val
6147 204779_s_at 7.367947 4.171874 72.77016 3.290669e-15 8.985500e-11
7292 207016_s_at 6.934796 4.027229 57.37259 3.712060e-14 5.068076e-10
8741 209631_s_at 5.193313 4.003541 51.22423 1.177337e-13 1.071612e-09
26309 242809_at 6.433514 4.167462 48.52518 2.042404e-13 1.394247e-09
6828 205893_at 4.480463 3.544350 40.59376 1.253534e-12 6.845801e-09
6222 204882_at -5.351976 6.512018 -34.70239 6.154318e-12 2.400711e-08
B gene.symbols
6147 20.25563 HOXB7
7292 19.44681 ALDH1A2
8741 18.96282 GPR37
26309 18.70767 IL1RL1
6828 17.75331 NLGN1
6222 16.77196 ARHGAP25
> write.table(results, "results.txt", sep="\t", quote=FALSE)
還有后續的 Simon Cockell 的分析差異表達的生物學意義教程,即 GO,kegg 等注釋,以及 Colin Gillespie 的差異表達分析可視化之火山圖教程。
最后附上教程中的代碼,請在確保你的文件夾中有已經編輯好的 phenodata.txt 文件之后再運行:
> # download the BioC installation routines
> source("http://bioconductor.org/biocLite.R")
> # install the core packages
> biocLite()
> # install the GEO libraries
> biocLite("GEOquery")
> library(GEOquery)
> getGEOSuppFiles("GSE20986")
> untar("GSE20986/GSE20986_RAW.tar", exdir="data")
> cels <- list.files("data/", pattern = "[gz]")
> sapply(paste("data", cels, sep="/"), gunzip)
> cels
> library(simpleaffy)
> celfiles<-read.affy(covdesc="phenodata.txt", path="data")
> celfiles
> celfiles.gcrma<-gcrma(celfiles)
> celfiles.gcrma
> # load colour libraries
> library(RColorBrewer)
> # set colour palette
> cols <- brewer.pal(8, "Set1")
> # plot a boxplot of unnormalised intensity values
> boxplot(celfiles, col=cols)
> # plot a boxplot of normalised intensity values, affyPLM required to interrogate celfiles.gcrma
> library(affyPLM)
> boxplot(celfiles.gcrma, col=cols)
> # the boxplots are somewhat skewed by the normalisation algorithm
> # and it is often more informative to look at density plots
> # Plot a density vs log intensity histogram for the unnormalised data
> hist(celfiles, col=cols)
> # Plot a density vs log intensity histogram for the normalised data
> hist(celfiles.gcrma, col=cols)
> # Perform probe-level metric calculations on the CEL files:
> celfiles.qc <- fitPLM(celfiles)
> # Create an image of GSM24662.CEL:
> image(celfiles.qc, which=1, add.legend=TRUE)
> # Create an image of GSM524665.CEL
> # There is a spatial artifact present
> image(celfiles.qc, which=4, add.legend=TRUE)
> # affyPLM also provides more informative boxplots
> # RLE (Relative Log Expression) plots should have
> # values close to zero. GSM524665.CEL is an outlier
> RLE(celfiles.qc, main="RLE")
> # We can also use NUSE (Normalised Unscaled Standard Errors).
> # The median standard error should be 1 for most genes.
> # GSM524665.CEL appears to be an outlier on this plot too
> NUSE(celfiles.qc, main="NUSE")
> eset <- exprs(celfiles.gcrma)
> distance <- dist(t(eset),method="maximum")
> clusters <- hclust(distance)
> plot(clusters)
> celfiles.filtered <- nsFilter(celfiles.gcrma, require.entrez=FALSE, remove.dupEntrez=FALSE)
> # What got removed and why?
> celfiles.filtered$filter.log
> samples <- celfiles.gcrma$Target
> # check the results of this
> samples
> # convert into factors
> samples<- as.factor(samples)
> # check factors have been assigned
> samples
> # set up the experimental design
> design = model.matrix(~0 + samples)
> colnames(design) <- c("choroid", "huvec", "iris", "retina")
> # inspect the experiment design
> design
> library(limma)
> # fit the linear model to the filtered expression set
> fit <- lmFit(exprs(celfiles.filtered$eset), design)
> # set up a contrast matrix to compare tissues v cell line
> contrast.matrix <- makeContrasts(huvec_choroid = huvec - choroid, huvec_retina = huvec - retina, huvec_iris = huvec - iris, levels=design)
> # check the contrast matrix
> contrast.matrix
> # Now the contrast matrix is combined with the per-probeset linear model fit.
> huvec_fits <- contrasts.fit(fit, contrast.matrix)
> huvec_ebFit <- eBayes(huvec_fits)
> # return the top 10 results for any given contrast
> # coef=1 is huvec_choroid, coef=2 is huvec_retina
> topTable(huvec_ebFit, number=10, coef=1)
> nrow(topTable(huvec_ebFit, coef=1, number=10000, lfc=5))
> nrow(topTable(huvec_ebFit, coef=1, number=10000, lfc=4))
> nrow(topTable(huvec_ebFit, coef=1, number=10000, lfc=3))
> nrow(topTable(huvec_ebFit, coef=1, number=10000, lfc=2))
> # Get a list for probesets with a four fold change or more
> probeset.list <- topTable(huvec_ebFit, coef=1, number=10000, lfc=4)
> biocLite("hgu133plus2.db")
> library(hgu133plus2.db)
> library(annotate)
> gene.symbols <- getSYMBOL(probeset.list$ID, "hgu133plus2")
> results <- cbind(probeset.list, gene.symbols)
> write.table(results, "results.txt", sep="\t", quote=FALSE)
工具善其事,必先利其器。
