為什么要關(guān)心字符編碼?
有時(shí)我們?yōu)g覽網(wǎng)頁(yè),或者使用 Windows 自帶的記事本查看包含非基礎(chǔ)拉丁字符的文件時(shí),會(huì)看到類似的現(xiàn)象:

「天吶,文字內(nèi)容看不懂,我打開是什么!」
「內(nèi)容沒(méi)法正常顯示,多半是字符編碼的鍋。」
此現(xiàn)象稱為「亂碼」,日語(yǔ)稱為文字化け,英語(yǔ)稱為 Mojibake(音譯自日語(yǔ))。「亂碼」改變的不僅僅是字形,連字符個(gè)數(shù)都將受影響;不光會(huì)大大影響閱讀,而且會(huì)在 web 上使你生產(chǎn)的內(nèi)容無(wú)法被搜索引擎識(shí)別。無(wú)論作為閱覽者,還是生產(chǎn)者,亂碼都是我們需要避免的問(wèn)題。
什么是字符編碼
首先,還要先提另一個(gè)概念:「字符集」。
「字符集」和「字符編碼」有什么關(guān)系嗎?
Charset is the set of characters you can use.
Encoding is the way these characters are store into memory.
摘自于 Stackoverflow.
「字符集」就是字符的集合,而「字符編碼」是字符如何存儲(chǔ)在計(jì)算機(jī)中的方式。舉個(gè)例子,Unicode 就是「字符集」,而 UTF-8 則是「字符編碼」。
有很多種不同的字符編碼,不同的字符編碼定義字符的方式也不一樣。例如每臺(tái)計(jì)算機(jī)都帶有的 ASCII 編碼,大陸常用的 GB2312, GB18030、臺(tái)灣常用的 BIG5,以及未來(lái)趨勢(shì) UTF-8。
UTF-8
最常見的 ASCII 采用 7 位表示一個(gè)字符,共課表達(dá) 128 個(gè)字符,僅能顯示基本拉丁字符,對(duì)于其他語(yǔ)言完全不夠,更加別提字符數(shù)量巨大的 CJK 地區(qū)字符。不管是大陸的 GB18030 或 臺(tái)灣的 BIG5,雖然能滿足中文使用,依然面臨諸多不便,例如如果海外的計(jì)算機(jī)不內(nèi)置這些編碼,則無(wú)法閱覽相關(guān)內(nèi)容。所以,企圖包含人類所有字符的字符集出現(xiàn)了:Unicode。目前(2017-03-06)最新版本為 9.0。
如此龐大的字符,如何為其編碼?Unicode 定制時(shí),計(jì)算機(jī)存儲(chǔ)器容量也大大增長(zhǎng)了。Unicode 采用 16 位表示一個(gè)字符,對(duì)于 ASCII 與其擴(kuò)展保持不變,剩下高位用 0 填滿。其他語(yǔ)言重新編碼。然后新的問(wèn)題來(lái)了:
原本拉丁字符只要占 1 個(gè)字節(jié),現(xiàn)在卻要花更多的空間。
UTF-8 還好的解決了這個(gè)問(wèn)題——采用變長(zhǎng)編碼的方式。UTF-8 使用 1~4 個(gè)字節(jié)表示一個(gè)字符。這里引用他人的描述:
- 如果一個(gè)字節(jié)的第一位為 0,那么代表當(dāng)前字符為單字節(jié)字符,占用一個(gè)字節(jié)的空間。0 之后的所有部分(7 個(gè) bit)代表在 Unicode 中的序號(hào)。
- 如果一個(gè)字節(jié)以 110 開頭,那么代表當(dāng)前字符為雙字節(jié)字符,占用 2 個(gè)字節(jié)的空間。110 之后的所有部分(5 個(gè) bit)加上后一個(gè)字節(jié)的除 10 外的部分(6 個(gè) bit)代表在 Unicode 中的序號(hào)。且第二個(gè)字節(jié)以 10 開頭
- 如果一個(gè)字節(jié)以 1110 開頭,那么代表當(dāng)前字符為三字節(jié)字符,占用 2 個(gè)字節(jié)的空間。110 之后的所有部分(5 個(gè) bit)加上后兩個(gè)字節(jié)的除 10 外的部分(12 個(gè) bit)代表在 Unicode 中的序號(hào)。且第二、第三個(gè)字節(jié)以 10 開頭
- 如果一個(gè)字節(jié)以 10 開頭,那么代表當(dāng)前字節(jié)為多字節(jié)字符的第二個(gè)字節(jié)。10 之后的所有部分(6 個(gè) bit)和之前的部分一同組成在 Unicode 中的序號(hào)。
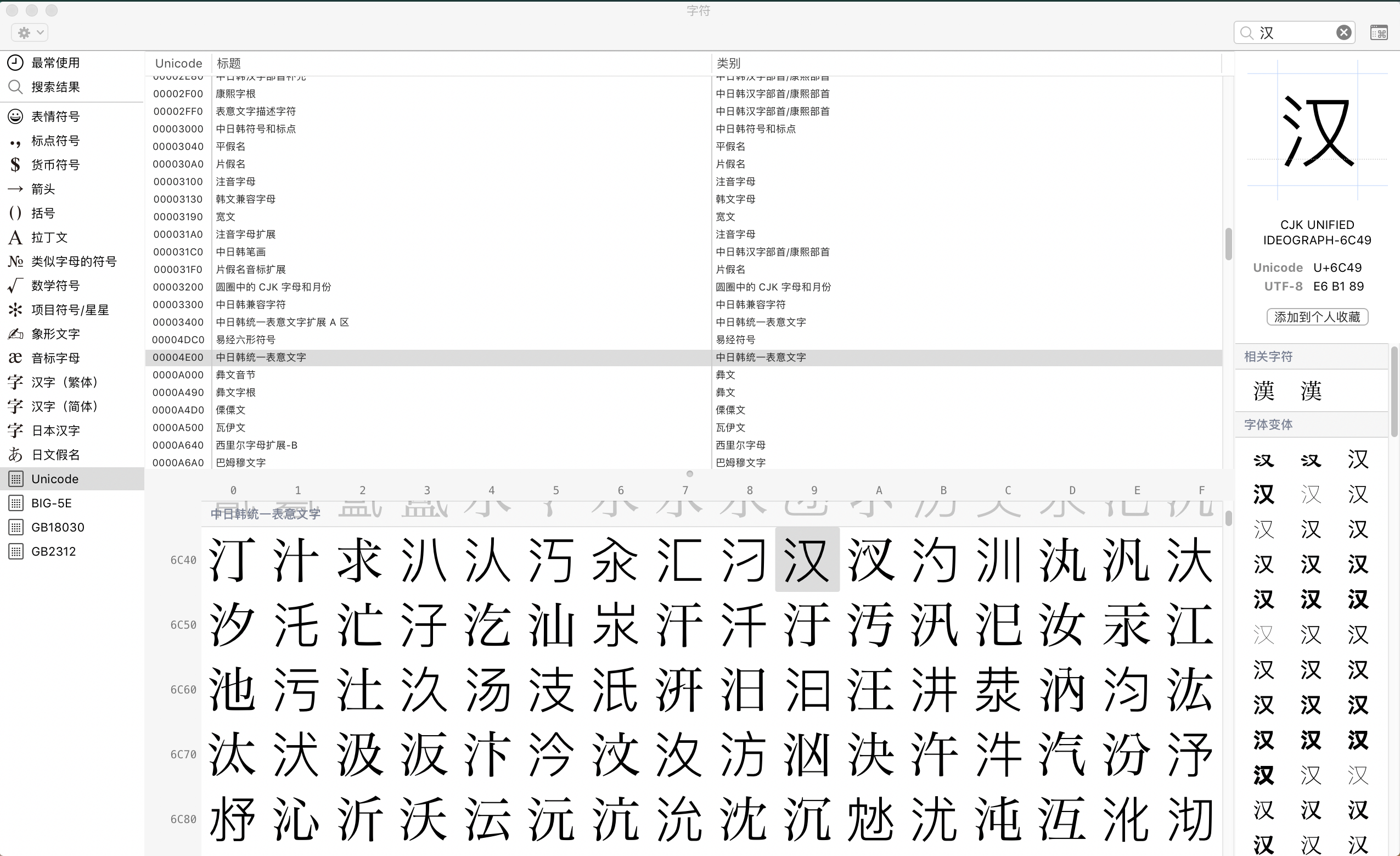
如何查找某個(gè)字符的編碼?
macOS 自帶的表情與符號(hào)可以找到字符在不同編碼方式下的碼位。