本篇翻譯自Denny Britz(Google Brain Team成員)的RNN系列教程
RNN也就是Recurrent Neural Network,在語音識別,自然語言處理(NLP)等很多領域廣泛應用,人氣很高。這個系列教程包含以下:
1、RNN簡介(本文)
2、使用Python和Theano實現RNN
3、了解方向傳播算法和梯度消失問題
4、實施GRU/LSTM RNN
本文假設你對基本的神經網絡有所了解。
什么是RNN?
RNN是按照時間維度的展開,代表信息在時間維度從前往后的的傳遞和積累,后面的信息的概率建立在前面信息的基礎上,在神經網絡結構上表現為后面的神經網絡的隱藏層的輸入是前面的神經網絡的隱藏層的輸出。
假定所有輸入(輸出)是相互獨立的,那這對于許多任務來說是扎心的。比如你想預測一個句子中的下一個單詞,單詞之間都獨立還預測個DD,跟妹子陌路,還想拉拉小手。另外RNN稱為循環因為它們是對序列的每個元素執行相同的任務,輸出取決于先前的計算。考慮RNN的另一種方法是,它們有一個“記憶”,捕獲到目前為止所計算的信息。在理論上RNN可以以任意長的序列來使用信息,但在實踐中,它們僅限反向幾步。一個典型的RNN:

上圖顯示了RNN正展開成一個完整的網絡。展開意味著我們寫出了完整序列的網絡。例如,如果我們關心的序列是5個字的句子,則網絡將被展開為5層神經網絡,每個單詞一層。RNN中計算的公式如下:
Xt是輸入t的時間步長。X1可以是對應于句子的第二個單詞的ont-hot 向量。
St是時間t時的隱藏狀態。它是構建網絡的“記憶”。St是基于以前的隱藏狀態和當前步驟的輸入計算的:st = f(Uxt + Wst-1)。該函數F通常是非線性的,如tanh或ReLU。 s-1存在是為了計算第一個隱藏狀態,通常全被初始化為零。
Ot是在t時的輸出。例如,如果我們想預測一個句子中的下一個單詞,會輸出一個詞匯概率的向量。
ot = softmax(Vst)。
這里有幾件事要注意:你可以將隱藏狀態ST視為網絡的記憶。ST捕獲所有先前time step中的信息。在時間t可以根據時間記憶計算出輸出Ot。如上所述,在實踐中有點復雜,因為ST通常無法從太長的時間捕獲信息。
不同于傳統的深層神經網絡,其在每個層使用不同的參數,RNN 在所有步驟中共享相同的參數(U,V,W)。這反映了我們在每個步驟上執行相同的任務,只用不同的輸入。那這大大減少了我們學習的參數數量。
上述圖表在每個time step都有輸出,但是根據任務,這不是必需的。例如,當預測句子的情緒時,我們可能只關心最終輸出,而不是每個單詞之后的情緒。類似地,我們可能不需要在每個time step都有輸入。RNN的主要特征是它的隱藏狀態并且能捕獲有關序列的一些信息。
RNN可以做什么?
在許多NLPtask中,RNN已經取得了巨大的成功。與此同時也想到了LSTM,是的它的長期依賴性要好于RNN。不用擔心的是LSTM與本教程中將要開發的RNN基本上是一樣的,它們只是具有不同的計算隱藏狀態的方法。我們將在稍后的文章中更詳細地介紹LSTM。以下是NLP中RNN的一些示例應用。
語言建模和生成文本
給定一系列單詞,我們想預測并給出先前任一單詞的概率。語言模型允許我們去衡量句子相似性,這是機器翻譯的重要輸入(因為高概率句子通常是正確的)。在能夠預測下一個單詞時會有一個slider-effect,它會得到一個生成模型,允許我們從輸出概率中抽樣生成新的文本。根據我們的訓練數據,我們可以生成各種各樣的東西。在語言建模中,我們的輸入通常是一系列單詞(例如,編碼為one-hot),我們的輸出是預測單詞的序列。我們構造ot = xt + 1可以在step t中的輸出單詞是實際中我們想要的。
關于語言建模和生成文本的研究論文:
機器翻譯
機器翻譯類似于語言建模,因為我們的輸入是一系列單詞(例如德語),輸出的是一系列的單詞(比如中文)。一個關鍵的區別是,我們的輸出只有在我們看到完整的輸入之后開始,因為翻譯的句子的第一個單詞可能需要從完整輸入序列中才能獲取。

機器翻譯研究論文
- A Recursive Recurrent Neural Network for Statistical Machine Translation
- Sequence to Sequence Learning with Neural Networks
- Joint Language and Translation Modeling with Recurrent Neural Networks
語音識別
給定來自聲波的聲信號的輸入序列,我們可以預測語音段的序列及其概率。
關于語音識別的研究論文:
生成圖像說明
與卷積神經網絡一起,RNN已被用作模型的一部分,以生成未標記圖像的描述。這是非常驚人的,這似乎是有效的。組合模型甚至將生成的單詞與圖像中發現的特征對齊。
如何訓練RNN
看了上面,RNN這么牛逼,那么怎么實現呢,不要著急,其實它類似訓練傳統的神經網絡,我們也使用反向傳播算法,不過是變化了下,由于參數由網絡中的所有time step共享,每個輸出的梯度不僅取決于當前time step的計算,而且還取決于以前的tiem step。例如,計算t = 4的梯度我們需要按照時間序列反向計算3個然后累加起來就是第四個時間的梯度,這稱為基于時間的反向傳播算法(BPTT)。要注意的是:RNNs的當層級比較多時(相距很遠的步驟之間存在依賴關系)由于梯度消失/爆炸問題在訓練上會存在一定的學習困難。當然,在業內也設計了一些類型(如LSTMs)避開這些問題。
RNN擴展
多年來,研究人員開發了更復雜類型的RNN來處理RNN模型的一些缺點。我們將在稍后的文章中更詳細地介紹這些內容,但是我希望本節作為簡概,可以讓讀者熟悉一些模型的分類。
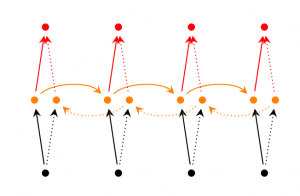
- 雙向RNNs(Bidirectional RNNs) 是一種當前時刻不僅僅取決于以前時刻同時還取決于未來時刻的RNN變體。舉個例子, 比如我的一段文本不僅僅和前面有關系, 還和后面有一定的關系,要預測序列中缺少的單詞,你要查看左側和右側上下文。雙向RNN非常簡單,你理解兩個堆疊在一起的RNN。然后基于兩個RNN的隱藏狀態來計算輸出。
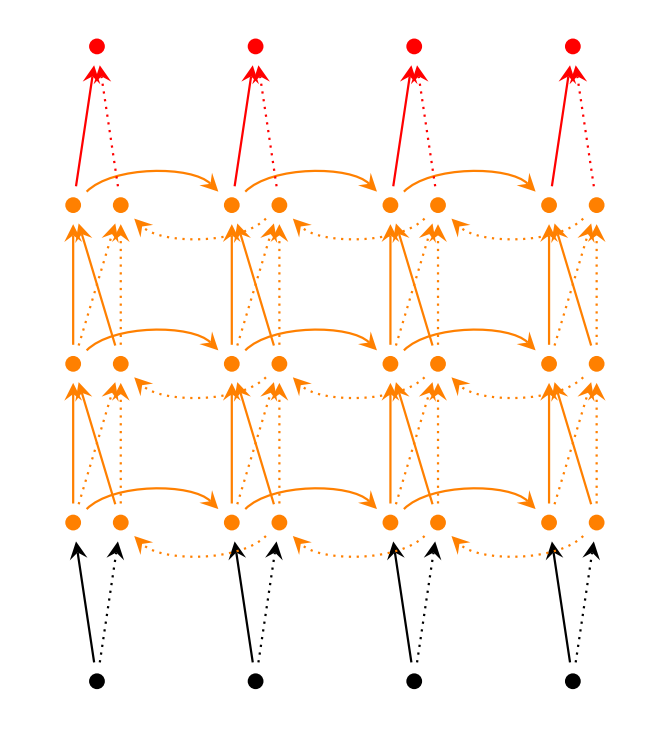
- LSTM RNNs(LSTM networks)是近幾年比較火的一種RNN變體, 實際上也是運用最為廣泛的一種形式, 它克服了梯度衰減問題, 這個問題在NN中也同樣存在, LSTM本身也有變體, 至少不下十幾種形式, 但是本質都差不多.
我的
簡書地址
uqlai`blog
擴展閱讀:
循環神經網絡(Recurrent)——介紹
