Apache Hadoop項目為高可用、可擴(kuò)展、分布式計算開發(fā)開源軟件。Apache Hadoop軟件庫是一個平臺,它使用簡單的編程模型讓跨機(jī)器上大數(shù)據(jù)量的分布式計算變得簡單。
它旨在從單個服務(wù)器擴(kuò)展到數(shù)千臺計算機(jī),每臺計算機(jī)都提供本地計算和存儲。庫本身被設(shè)計用來在軟件層面檢測和處理故障,而不是依賴硬件來提供高可用性,因此,在計算機(jī)集群之上提供高可用性服務(wù),每個計算機(jī)都可能容易出現(xiàn)故障。
介紹
HDFS是一個被設(shè)計用來運(yùn)行在商用機(jī)器上的分布式文件系統(tǒng)。它跟現(xiàn)有的分布式文件系統(tǒng)有很多相似之處,但是,區(qū)別也很大。HDFS容錯率高,并且被設(shè)計為部署在廉價機(jī)器上。HDFS提供對應(yīng)用程序數(shù)據(jù)的高吞吐量訪問,適用于具有大型數(shù)據(jù)集的應(yīng)用程序。HDFS放寬了一些POSIX要求,以實(shí)現(xiàn)對文件系統(tǒng)數(shù)據(jù)的流式訪問。HDFS最開始被構(gòu)建是用來作為Nutch搜索引擎項目的基礎(chǔ)設(shè)施。HDFS是Apache hadoop核心項目的一部分。項目地址:http://hadoop.apache.org/
假設(shè)和目標(biāo)
硬件故障
硬件故障很常見。一個HDFS示例應(yīng)該是包含成百上千臺服務(wù)器,每臺服務(wù)器保存文件系統(tǒng)的部分?jǐn)?shù)據(jù)。事實(shí)上,存在大量組件并且每個組件都有可能出現(xiàn)故障,這意外著有些組件可能一直無法正常工作。因此,檢測故障并且自動從故障中快速恢復(fù)是HDFS架構(gòu)的核心目標(biāo)。
流數(shù)據(jù)訪問
在HDFS上運(yùn)行的程序需要對其數(shù)據(jù)集進(jìn)行流式訪問。它們不是運(yùn)行在普通文件系統(tǒng)上的普通應(yīng)用程序。HDFS被設(shè)計更多是作為批處理來使用,而不是用戶的交互式使用。重點(diǎn)是數(shù)據(jù)訪問的高吞吐量而不是數(shù)據(jù)訪問的低延遲。POSIX強(qiáng)加了許多針對HDFS的應(yīng)用程序不需要的硬性要求。
大數(shù)據(jù)集
運(yùn)行在HDFS上的程序用戶大量的數(shù)據(jù)集。HDFS中,一個普通文件可以達(dá)到千兆到太字節(jié)。因此,HDFS調(diào)整為支持大文件。它應(yīng)該提供高聚合數(shù)據(jù)帶寬并擴(kuò)展到單個集群中的數(shù)百個節(jié)點(diǎn)。 它應(yīng)該在單個實(shí)例中支持?jǐn)?shù)千萬個文件。
簡單的一致性模型
HDFS程序需要一個一次寫入多次讀取的文件訪問模型。一次創(chuàng)建、寫入和關(guān)閉的文件,除了追加和截斷之外,不需要更改。可以在文件尾部追加內(nèi)容,但是不能在任意位置進(jìn)行修改。這種假設(shè)簡化了一致性問題,并且提高了數(shù)據(jù)訪問的吞吐量。這種模型非常適合Mapreduce程序以及網(wǎng)絡(luò)爬蟲。
移動計算比移動數(shù)據(jù)代價更小
當(dāng)計算所需要的數(shù)據(jù)距離計算越近時,計算的效率越高,當(dāng)數(shù)據(jù)量越大時,這個效率提升更明顯。越少的網(wǎng)絡(luò)阻塞越能提高系統(tǒng)整體的吞吐量。這樣,我們可以認(rèn)為,將計算遷移到數(shù)據(jù)附近比將數(shù)據(jù)遷移到計算附近更高效。HHDFS為應(yīng)用程序提供了接口,使其自身更靠近數(shù)據(jù)所在的位置。
跨異構(gòu)硬件和軟件平臺的可移植性
HDFS被設(shè)計成易于從一個平臺移植到另一個平臺。這有助于HDFS的普及。
Namenode和DataNodes
HDFS有一個主從架構(gòu)。一個HDFS集群包含一個Namenode,Namenode管理文件系統(tǒng)的命名空間以及調(diào)整客戶端對文件的訪問。此外,還有一定數(shù)量的Datanode,集群中通常一個節(jié)點(diǎn)一個Datanode,用來管理其運(yùn)行節(jié)點(diǎn)上的存儲。HDFS公開文件系統(tǒng)命名空間,并允許用戶數(shù)據(jù)存儲在文件中。集群內(nèi)部,一個文件被分成一個或多個blocks并且這些blocks存儲在一些Datanode上。Namenode執(zhí)行文件系統(tǒng)命名空間操作,例如打開、關(guān)閉、重命名文件和文件夾。Namenode還決定blocks到Datanode的映射。Datanode負(fù)責(zé)服務(wù)于系統(tǒng)客戶端的讀和寫。DataNode還根據(jù)NameNode的指令執(zhí)行塊創(chuàng)建,刪除和復(fù)制。

Namenode和Datanode時設(shè)計用于運(yùn)行在商用機(jī)器上的軟件。這些機(jī)器通常運(yùn)行l(wèi)inux操作系統(tǒng)。HDFS是JAVA語言編寫的,所以任何支持JAVA的機(jī)器都能運(yùn)行Namenode和Datanode軟件。使用高度可移植的Java語言意味著HDFS可以部署在各種各樣的機(jī)器上。普遍的部署方式是在一臺專用機(jī)器上單獨(dú)運(yùn)行Namenode軟件。集群中其他機(jī)器運(yùn)行Datanode軟件。架構(gòu)支持在一臺機(jī)器上運(yùn)行多個Datanode,但是實(shí)際部署很少這樣做。
一個集群中只存在一個Namenode極大簡化了系統(tǒng)的架構(gòu)。Namenode管理整個HDFS的元數(shù)據(jù)。系統(tǒng)被設(shè)計為任何用戶數(shù)據(jù)都不流經(jīng)Namenode。
文件系統(tǒng)命名空間
HDFS支持傳統(tǒng)的文件分層組織。用戶或程序可以創(chuàng)建目錄以及保存文件到目錄中。HDFS文件系統(tǒng)命名空間層次結(jié)構(gòu)跟其他現(xiàn)有文件系統(tǒng)類似:比如創(chuàng)建文件和刪除文件,將文件從一個目錄移到另一個目錄,或者重命名文件。HDFS支持用戶配額和訪問權(quán)限。HDFS不支持硬連接或軟連接,但是不排除在未來的版本中實(shí)現(xiàn)。
Namenode維護(hù)文件系統(tǒng)的命名空間。文件系統(tǒng)命名空間或其屬性的更改都由Namenode來記錄。應(yīng)用程序可以指定文件的副本數(shù)量,該文本由HDFS來維護(hù)。文件的副本數(shù)稱為該文件的復(fù)制因子,該信息由NameNode存儲。
數(shù)據(jù)復(fù)制
HDFS被設(shè)計用來可靠地在集群中大量機(jī)器上存儲大文件。它以一系列塊的形式保存每一個文件。文件塊被復(fù)制多份以提高容錯性。每個文件的塊大小和復(fù)制因子是可配置的。
一個文件除了最后一個塊以外,其他塊都是相同大小。當(dāng)設(shè)置塊長度可變時,用戶可以開啟一個新的塊而不需要在最后的塊上進(jìn)行追加以達(dá)到配置的固定大小。
應(yīng)用程序可以指定文件的副本數(shù)量。復(fù)制因子在文件創(chuàng)建時指定并能在隨后進(jìn)行修改。HDFS中文件是一次性寫入(除非追加和截斷)并且任何時候只有一個寫入者。
有關(guān)塊的復(fù)制,NameNode全權(quán)負(fù)責(zé)。Namenode定期接收集群中Datanode的心跳和塊信息報告。接收到心跳表明Datanode正常工作。塊信息報告(Blockreport)包含DataNode上所有塊的列表。
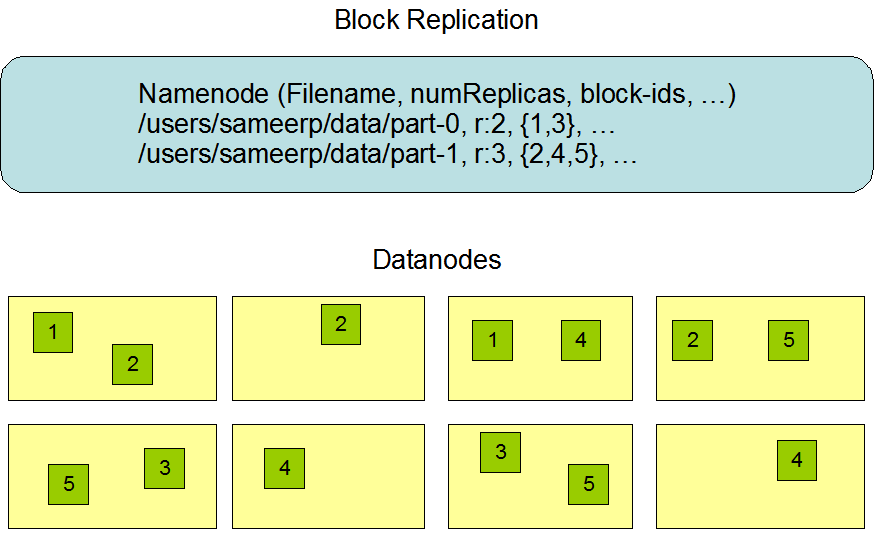
副本選址
副本的選址對HDFS的可靠性和性能起到至關(guān)重要的作用。優(yōu)化副本的選址使HDFS區(qū)別于其他分布式文件系統(tǒng)。這是一個需要大量調(diào)試和經(jīng)驗的特性。機(jī)架感知式的選址策略的目標(biāo)是為了提供數(shù)據(jù)可靠性、可用性以及帶寬利用率。目前的副本選址策略的實(shí)現(xiàn)是在這個方向上的第一次努力。實(shí)現(xiàn)這個策略的短期目標(biāo)是在生產(chǎn)系統(tǒng)中進(jìn)行驗證,掌握更多行為并建立一個基礎(chǔ)來測試和研究更加復(fù)雜的策略。
HDFS運(yùn)行在一系列的集群主機(jī)上,這些主機(jī)通常分布在各個機(jī)架上。跨機(jī)架上的兩個不同主機(jī)間信息交換需要經(jīng)過交換機(jī)。在大多數(shù)情況下,同一機(jī)架中的計算機(jī)之間的網(wǎng)絡(luò)帶寬大于不同機(jī)架中的計算機(jī)之間的網(wǎng)絡(luò)帶寬。
Namenode通過Hadoop Rack Awareness 過程來決定每個Datanode隸屬于哪個機(jī)架id。一個簡單但是非最佳的策略是將副本放在不同機(jī)架上。這樣,當(dāng)一整個機(jī)架出現(xiàn)故障時能夠防止數(shù)據(jù)丟失,并且讀取數(shù)據(jù)能使用到不同機(jī)架上的帶寬。但是,這種策略增加了寫操作代價,因為需要傳輸塊到不同機(jī)架上。
當(dāng)副本數(shù)為3時,HDFS放置策略通常是將一個副本放在本機(jī)架的一個節(jié)點(diǎn)上,將另一個副本放在本機(jī)架的另一個節(jié)點(diǎn),最后一個副本放在不同機(jī)架的不同節(jié)點(diǎn)上。該策略可以減少機(jī)架之間寫入流量,從而提高寫入性能。機(jī)架出現(xiàn)故障的概率要比機(jī)器出現(xiàn)故障的概率低,這個策略不會影響數(shù)據(jù)可靠性和可用性的保證。但這種策略會降低數(shù)據(jù)讀取時的網(wǎng)絡(luò)帶寬,因為數(shù)據(jù)只放置在兩個機(jī)架上而不是三個。這種策略下,文件的副本不是均勻的分布在各個機(jī)架上。三分一個的副本放置在一個節(jié)點(diǎn)上,三分之二的副本放置在一個機(jī)架上,而另外三分之一均勻分布在剩余的機(jī)架上。這個策略提高了寫性能而不影響數(shù)據(jù)可靠性和讀性能。
當(dāng)前,這里介紹的默認(rèn)副本放置策略是一項正在進(jìn)行的工作。
副本選擇
為了降低帶寬消耗以及讀取延時,HDFS嘗試讓需要讀取的副本跟讀取者更近。如果存在一個副本在客戶端節(jié)點(diǎn)所在的同個機(jī)架上,那么這個副本是滿足讀取需求的首選。如果HDFS集群橫跨多個數(shù)據(jù)中心,那么在本地數(shù)據(jù)中心的副本將是優(yōu)先于其他遠(yuǎn)程副本。
安全模式
Namenode剛啟動時會進(jìn)入一個特殊階段,我們稱這個階段為安全模式。當(dāng)Namenode處于安全模式時,不會發(fā)生數(shù)據(jù)塊的復(fù)制。Namenode接收來自Datanode的心跳以及塊報告信息。塊報告包含Datanode持有的一些列數(shù)據(jù)塊。每個塊都指定最小副本數(shù)。當(dāng)一個數(shù)據(jù)塊被NameNode檢查確保它滿足最小副本時數(shù),它被認(rèn)為是安全的。數(shù)據(jù)被Namenode檢入,當(dāng)檢入達(dá)到一個百分比(該百分比可配置)時,Namenode退出安全模式。然后Namenode會確認(rèn)那些副本數(shù)小于指定數(shù)量的數(shù)據(jù)塊列表,并且復(fù)制這些塊到其他Datanode上。
文件系統(tǒng)元數(shù)據(jù)的持久性
HDFS命名空間保存在Namenode上。NmaeNode使用一個稱之為EditLog的事務(wù)日志持續(xù)地記錄發(fā)生在文件系統(tǒng)元數(shù)據(jù)的每一個改變。例如,在HDFS中創(chuàng)建一個文件,Namenode將插入一條記錄到EditLog中。同樣,修改文件的復(fù)制因子也會導(dǎo)致一條新的記錄插入EditLog中。Namenode使用本地操作系統(tǒng)文件來保存EditLog。整個文件系統(tǒng)命名空間(包括塊到文件的映射以及文件系統(tǒng)屬性)存儲在一個稱為FsImage的文件中。FsImage同樣存儲在Namenode的本地文件系統(tǒng)中。
Namenode將整個文件系統(tǒng)的命名空間以及塊映射信息保存在內(nèi)存中。當(dāng)Namenode啟動時,或者可配置閾值的檢查點(diǎn)被觸發(fā)時,Namenode便從磁盤中讀取FsImage和EditLog,將EditLog中的事務(wù)應(yīng)用到表示FsImage的內(nèi)存中,然后將最新的FsImage內(nèi)存刷新到磁盤上。然后可以截斷舊的EditLog,因為新版的EditLog已經(jīng)持久化到FsImage中。以上整個過程稱為檢查點(diǎn)(checkpoint)。檢查點(diǎn)的目的是通過獲取文件系統(tǒng)元數(shù)據(jù)的快照并將其保存到FsImage來確保HDFS具有文件系統(tǒng)元數(shù)據(jù)的一致視圖。即使讀取FsImage很高效,直接向FsImage增加編輯并不高效。因此針對每次編輯,我們會放在EditLog中而不是直接修改FsImage。檢查點(diǎn)期間,EditLog的變更信息會應(yīng)用到FsImage上。可以以秒為單位的給定時間間隔(dfs.namenode.checkpoint.period)觸發(fā)檢查點(diǎn),或者在累積給定數(shù)量的文件系統(tǒng)事務(wù)(dfs.namenode.checkpoint.txns)之后觸發(fā)檢查點(diǎn)。當(dāng)兩者均被設(shè)置,則哪個先生效就直接觸發(fā)檢查點(diǎn)。
Datanode將HDFS數(shù)據(jù)保存在本地文件系統(tǒng)的文件中。Datanode對HDFS文件沒有意識,它只是保存HDFS數(shù)據(jù)的每個塊,并保存在本地文件系統(tǒng)中的各個文件中。Datanode不會在相同目錄下創(chuàng)建所有文件,而是每個目錄中有一個最佳文件數(shù),并適當(dāng)創(chuàng)建子目錄。將所有文件放在同一個目錄下不太明智,因為本地文件系統(tǒng)或許不能有效支持在一個目錄下面存放海量文件。當(dāng)一個Datanode啟動時,它將掃描本地文件系統(tǒng),生成所有HDFS數(shù)據(jù)塊的列表(這些數(shù)據(jù)塊對應(yīng)每一個本地文件),并發(fā)送報告給Namenode。這個報告我們稱之為塊報告。
通訊協(xié)議
所有HDFS協(xié)議均位于TCP/IP之上。一個客戶端建立一個連接到Namenode機(jī)器上的TCP端口(端口可配置)上。它使用客戶端協(xié)議與NameNode通訊。Datanode使用Datanode協(xié)議與Namenode進(jìn)行通訊。一個遠(yuǎn)程過程調(diào)用(RPC)封裝了客戶端協(xié)議以及Datanode協(xié)議。按照設(shè)計,NameNode永遠(yuǎn)不會啟動任何RPC。 相反,它只響應(yīng)DataNodes或客戶端發(fā)出的RPC請求。
魯棒性
HDFS的主要目標(biāo)是即使在出現(xiàn)故障時也能可靠地存儲數(shù)據(jù)。三種常見的故障有:Namanode故障、Datanode故障以及網(wǎng)絡(luò)分裂?
數(shù)據(jù)磁盤故障,心跳以及重新復(fù)制
每個Datanode會定期地發(fā)送心跳信息給你Namenode。網(wǎng)絡(luò)分裂會導(dǎo)致部分Datanode失去與Namenode的聯(lián)系。Namenode通過收不到Datanode的心跳信息來收集這個失聯(lián)信息。Namenode標(biāo)記近期沒有心跳信息的Datanode,并終止對這些Datanode的IO請求。在已經(jīng)死亡的DataNode注冊的任何數(shù)據(jù)在HDFS將不能再有效。Datanode故障會導(dǎo)致一些塊的復(fù)制因子低于它們的指定值。NameNode時常地跟蹤數(shù)據(jù)塊是否需要被復(fù)制并在必要的時候啟動復(fù)制。多個原因會導(dǎo)致重新復(fù)制的操作,例如:Datanode不可用,副本損壞,Datanode磁盤損壞,或者文件的復(fù)制因子增大。
將DatNode標(biāo)記為死亡的超時時間適當(dāng)?shù)丶娱L(默認(rèn)超過10分鐘)是為了避免DataNode狀態(tài)改變引起的復(fù)制風(fēng)暴。針對性能敏感的情況,用戶可以通過配置來設(shè)置更短的時間間隔來標(biāo)記DataNode為失效,盡量避免失效的節(jié)點(diǎn)還繼續(xù)參與讀寫操作。
集群重新平衡
HDFS架構(gòu)兼容數(shù)據(jù)再平衡方案。當(dāng)一個Datanode上的剩余空間降到一定閾值時,方案應(yīng)該自動將該Datanode上的數(shù)據(jù)遷移到其他Datanode上。對于一些特定文件的突發(fā)需求,方案應(yīng)動態(tài)地創(chuàng)建額外的副本并重新平衡集群中的其他數(shù)據(jù)。這種方案暫時還未實(shí)現(xiàn)。
數(shù)據(jù)完整性
從DataNode獲取的數(shù)據(jù)塊可能已損壞。發(fā)生損壞的原因可能是存儲設(shè)備的故障、網(wǎng)絡(luò)故障或者缺陷軟件。HDFS客戶端軟件對HDFS文件的內(nèi)容進(jìn)行校驗和檢查。當(dāng)客戶端創(chuàng)建一個HDFS文件,它會計算文件的每一個數(shù)據(jù)塊的校驗和,并將這些校驗和儲存在HDFS命名空間中一個單獨(dú)的隱藏的文件當(dāng)中。當(dāng)客戶端從DataNode獲得數(shù)據(jù)時會對對其進(jìn)行校驗和,并且將之與儲存在相關(guān)校驗和文件中的校驗和進(jìn)行匹配。如果沒有,客戶端會選擇從另一個擁有該數(shù)據(jù)塊副本的DataNode上恢復(fù)數(shù)據(jù)。
元數(shù)據(jù)磁盤故障
FsImage和EditLog是HDFS的核心數(shù)據(jù)架構(gòu)。這些文件的故障會導(dǎo)致HDFS實(shí)例無法工作。因為這個原因,HDFS可以被配置成支持多份FsImage和EditLog備份。任何對FsImage和EditLog的更新,都會導(dǎo)致其他所有FsImage和EditLog的同步更新。同步更新多份FsImge和EditLog降低NameNode能支持的每秒更新命名空間事務(wù)的頻率。然而,頻率的降低是可以被接受,盡管HDFS應(yīng)用本質(zhì)上是對數(shù)據(jù)敏感,但不是對元數(shù)據(jù)敏感。當(dāng)一個NameNode重新啟動,他會選擇最新的FsImage和EditLog來使用。另一個增加容錯性已達(dá)到高可用性的選項是使用多個Namenodes,這個選項的具體實(shí)現(xiàn)可以為:文件系統(tǒng)的共享存儲、分布式的編輯日志(稱為Journal)。后面會介紹使用方法。
快照
快照支持在特定的時間(瞬間)保存數(shù)據(jù)的副本。我們使用的快照特征可能是將損壞的HDFS實(shí)例回退到先前一個正常版本。
Data Organization
數(shù)據(jù)塊
HDFS被設(shè)計成支持非常大的文件。與HDFS兼容的應(yīng)用程序是處理大型數(shù)據(jù)集的應(yīng)用程序。這些程序一次寫入數(shù)據(jù)多次讀取,并且這些讀操作滿足流式的速度。HDFS支持一次寫入多次讀取的文件語義。HDFS中,一個典型的塊大小是128兆。因此,一個HDFS文件會被切割成128M大小的塊,如果可以的話,每一個大塊都會分屬于一個不同的DatNode。
復(fù)制流水線
當(dāng)客戶端按照3個副本數(shù)來寫數(shù)據(jù)到HDFS文件中,Namenode使用副本目標(biāo)選擇算法來獲取Datanode列表。這個列表包含塊副本將落地的Datanode。然后客戶端將數(shù)據(jù)寫入第一個Datanode。第一個Datanode開始分部分接收數(shù)據(jù),將每個部分寫入其本地存儲,并將該部分傳輸?shù)搅斜碇械牡诙€Datanode。第二個Datanode開始接收數(shù)據(jù)塊的每個部分并寫入本地存儲然后傳輸?shù)降谌齻€Datanode。最后,第三個Datanode將數(shù)據(jù)寫入本地存儲。因此,一個Dataode能夠從上一個節(jié)點(diǎn)接收數(shù)據(jù)據(jù)并在同一時間將數(shù)據(jù)轉(zhuǎn)發(fā)給下一個節(jié)點(diǎn)。因此,數(shù)據(jù)在管道中從一個DataNode傳輸?shù)较乱粋€(復(fù)制流水線)。
可訪問性
應(yīng)用程序可以通過多種方式來訪問HDFS。HDFS本身提供FileSystem Java API讓應(yīng)用程序來訪問,這個Java Api的C語言封裝版本以及REST API同樣可以供用戶使用。另外,一個HTTP瀏覽器也可以訪問HDFS實(shí)例中的文件。使用MFS gateway,HDFS能被安裝作為本地文件系統(tǒng)的一部分。
FS Shell
HDFS提供一個稱為FS Shell的命令行接口,方便用戶與HDFS中的數(shù)據(jù)進(jìn)行交互。這寫命令集合的語法跟其他我們熟悉的命令十分相似(例如bash,csh)。下面是一些動作/命令對的示例:
| 動作 | 命令 |
|---|---|
| 創(chuàng)建目錄 | bin/hadoop dfs -mkdir /foodir |
| 刪除目錄 | bin/hadoop fs -rm -R /foodir |
| 查看文件內(nèi)容 | bin/hadoop dfs -cat /foodir/myfile.txt |
DFSAdmin
DFSAdmin命令集是用來管理HDFS集群。只有HDFS管理者才能使用這些命令。下面是一些動作/命令對的示例:
| 動作 | 命令 |
|---|---|
| Put the cluster in Safemode | bin/hdfs dfsadmin -safemode enter |
| Generate a list of DataNodes | bin/hdfs dfsadmin -report |
| Recommission or decommission DataNode(s) | bin/hdfs dfsadmin -refreshNode |
瀏覽器界面
A typical HDFS install configures a web server to expose the HDFS namespace through a configurable TCP port. This allows a user to navigate the HDFS namespace and view the contents of its files using a web browser.
通常安裝HDFS時會配置一個web服務(wù),通過一個配置好的TCP端口來暴露HDFS命名空間。它允許用戶看到HDFS命名空間,并能使用web瀏覽器來查看文件內(nèi)容。
空間回收
文件的刪除和恢復(fù)
如果垃圾配置可用,使用HDFS SHELL刪除的文件不會立刻從HDFS刪除,而是被移動到垃圾目錄(每個用戶都有自己的垃圾目錄:/user/<username>/.Trash),文件只要在垃圾目錄中,可以隨時進(jìn)行恢復(fù)。
大部分剛刪除的文件都被移動到垃圾目錄中(/user/<username>/.Trash/Current),并且在一個可配置的間隔時間內(nèi),HDFS為當(dāng)前垃圾目錄中的文件創(chuàng)建檢查點(diǎn)(under /user/<username>/.Trash/<date>),同時刪除那些過期的檢查點(diǎn)。垃圾檢查點(diǎn)信息請點(diǎn)擊expunge command of FS shell
當(dāng)回收站中的文件過期后,Namenode會從HDFS命名空間中刪除該文件。文件的刪除會導(dǎo)致跟該文件相關(guān)聯(lián)的塊被釋放。需要說明的是文件被用戶刪除的時間和對應(yīng)的釋放空間的時間之間有一個明顯的時間延遲。
下面的例子將展示如何通過FS SHELL將文件從HDFS中刪除。我們在要刪除的目錄中創(chuàng)建test1和test2兩個文件
$ hadoop fs -mkdir -p delete/test1
$ hadoop fs -mkdir -p delete/test2
$ hadoop fs -ls delete/
Found 2 items
drwxr-xr-x - hadoop hadoop 0 2015-05-08 12:39 delete/test1
drwxr-xr-x - hadoop hadoop 0 2015-05-08 12:40 delete/test2
我們將刪除test1文件,下面的日志顯示文件被移動到垃圾目錄中
$ hadoop fs -rm -r delete/test1
Moved: hdfs://localhost:8020/user/hadoop/delete/test1 to trash at: hdfs://localhost:8020/user/hadoop/.Trash/Current
現(xiàn)在我來執(zhí)行將文件刪除跳過垃圾目錄選項(skipTrash),文件則不會轉(zhuǎn)移到垃圾目錄。文件將完全從HDFS中移除。
$ hadoop fs -rm -r -skipTrash delete/test2
Deleted delete/test2
現(xiàn)在在垃圾目錄中,我們只能看到test1文件
$ hadoop fs -ls .Trash/Current/user/hadoop/delete/
Found 1 items\
drwxr-xr-x - hadoop hadoop 0 2015-05-08 12:39 .Trash/Current/user/hadoop/delete/test1
也就是test1進(jìn)入垃圾目錄,而test2被永久刪除。
復(fù)制因子減少
當(dāng)文件的復(fù)制因子減小時,NameNode將在可以刪除的副本中選中多余的副本。在下一個心跳通訊中將該信息傳輸給DataNode。然后DataNode移除對應(yīng)的數(shù)據(jù)塊并且釋放對應(yīng)的空間。再重申一遍,在完成復(fù)制因子的設(shè)置和集群中出現(xiàn)新的空間之間有個時間延遲。
參考
Hadoop Java API
HDFS源碼: http://hadoop.apache.org/version_control.html
