
本文cmd地址:經(jīng)典檢索算法:BM25原理
bm25 是什么?
bm25 是一種用來評價搜索詞和文檔之間相關(guān)性的算法,它是一種基于概率檢索模型提出的算法,再用簡單的話來描述下bm25算法:我們有一個query和一批文檔Ds,現(xiàn)在要計算query和每篇文檔D之間的相關(guān)性分數(shù),我們的做法是,先對query進行切分,得到單詞$q_i$,然后單詞的分數(shù)由3部分組成:
- 單詞$q_i$和D之間的相關(guān)性
- 單詞$q_i$和D之間的相關(guān)性
- 每個單詞的權(quán)重
最后對于每個單詞的分數(shù)我們做一個求和,就得到了query和文檔之間的分數(shù)。
bm25 解釋
講bm25之前,我們要先介紹一些概念。
二值獨立模型 BIM
BIM(binary independence model)是為了對文檔和query相關(guān)性評價而提出的算法,BIM為了計算$P(R|d,q)$,引入了兩個基本假設(shè):
假設(shè)1
一篇文章在由特征表示的時候,只考慮詞出現(xiàn)或者不出現(xiàn),具體來說就是文檔d在表示為向量$\vec x=(x_1,x_2,...,x_n)$,其中當(dāng)詞$t$出現(xiàn)在文檔d時,$x_t=1$,否在$x_t=0$。
假設(shè)2
文檔中詞的出現(xiàn)與否是彼此獨立的,數(shù)學(xué)上描述就是$P(D)=\sum_{i=0}^n P(x_i)$
有了這兩個假設(shè),我們來對文檔和query相關(guān)性建模:
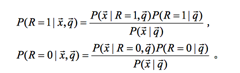
其中

接著因為我們最終得到的是一個排序,所以,我們通過計算文檔和query相關(guān)和不相關(guān)的比率,也可得文檔的排序,有下面的公式:

其中


由于每個 xt 的取值要么為 0 要么為 1,所以,我們可得到:
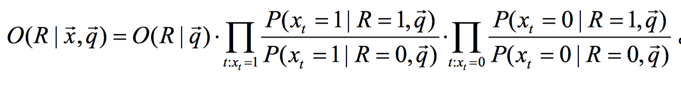
我們接著引入一些記號:


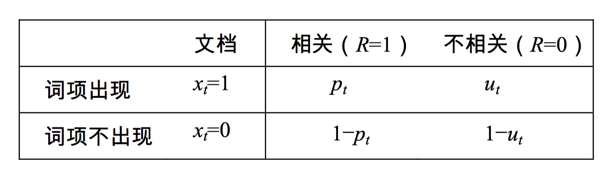
于是我們就可得到:

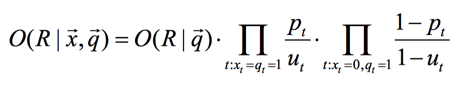
我們接著做下面的等價變換:
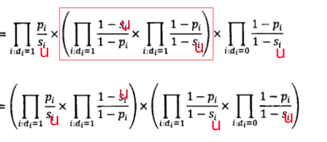

此時,公式中
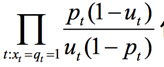

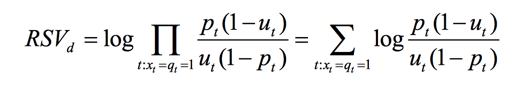
定義單個詞的ct

下一步我們要解決的就是怎么去估計pt和ut,看下表:

其中dft是包含詞t的文檔總數(shù),于是

此時詞t的ct值是:
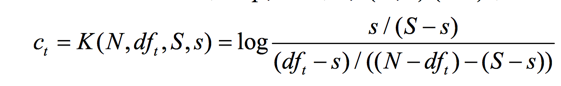
為了做平滑處理,我們都加上1/2,得到:

在實際中,我們很難知道t的相關(guān)文檔有多少,所以假設(shè)S=s=0,所以:
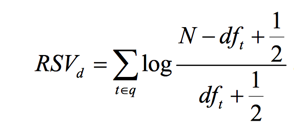
其中N是總的文檔數(shù),dft是包含t的文檔數(shù)。
以上就是BIM的主要思想,后來人們發(fā)現(xiàn)應(yīng)該講BIM中沒有考慮到的詞頻和文檔長度等因素都考慮進來,就有了后面的BM25算法,下面按照
- 單詞t和D之間的相關(guān)性
- 單詞t和D之間的相關(guān)性
- 每個單詞的權(quán)重
3個部分來介紹bm25算法。
單詞權(quán)重
單詞的權(quán)重最簡單的就是用idf值,即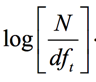
,也就是有多少文檔包含某個單詞信息進行變換。如果在這里使用 IDF 的話,那么整個 BM25 就可以看作是一個某種意義下的 TF-IDF,只不過 TF 的部分是一個復(fù)雜的基于文檔和查詢關(guān)鍵字、有兩個部分的詞頻函數(shù),還有一個就是用上面得到的ct值。
單詞和文檔的相關(guān)性
tf-idf中,這個信息直接就用“詞頻”,如果出現(xiàn)的次數(shù)比較多,一般就認為更相關(guān)。但是BM25洞察到:詞頻和相關(guān)性之間的關(guān)系是非線性的,具體來說,每一個詞對于文檔相關(guān)性的分數(shù)不會超過一個特定的閾值,當(dāng)詞出現(xiàn)的次數(shù)達到一個閾值后,其影響不再線性增長,而這個閾值會跟文檔本身有關(guān)。
在具體操作上,我們對于詞頻做了”標(biāo)準化處理“,具體公式如下:

其中,tftd 是詞項 t 在文檔 d 中的權(quán)重,Ld 和 Lave 分別是文檔 d 的長度及整個文檔集中文檔的平均長度。k1是一個取正值的調(diào)優(yōu)參數(shù),用于對文檔中的詞項頻率進行縮放控制。如果 k 1 取 0,則相當(dāng)于不考慮詞頻,如果 k 1取較大的值,那么對應(yīng)于使用原始詞項頻率。b 是另外一個調(diào)節(jié)參數(shù) (0≤ b≤ 1),決定文檔長度的縮放程度:b = 1 表示基于文檔長度對詞項權(quán)重進行完全的縮放,b = 0 表示歸一化時不考慮文檔長度因素。
單詞和查詢的相關(guān)性
如果查詢很長,那么對于查詢詞項也可以采用類似的權(quán)重計算方法。
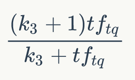
其中,tftq是詞項t在查詢q中的權(quán)重。這里k3 是另一個取正值的調(diào)優(yōu)參數(shù),用于對查詢中的詞項tq 頻率進行縮放控制。
于是最后的公式是:

bm25 gensim中的實現(xiàn)
gensim在實現(xiàn)bm25的時候idf值是通過BIM公式計算得到的:

然后也沒有考慮單詞和query的相關(guān)性。

其中幾個關(guān)鍵參數(shù)取值:
PARAM_K1 = 1.5
PARAM_B = 0.75
EPSILON = 0.25
此處EPSILON是用來表示出現(xiàn)負值的時候怎么獲取idf值的。
總結(jié)下本文的內(nèi)容:BM25是檢索領(lǐng)域里最基本的一個技術(shù),BM25 由三個核心的概念組成,包括詞在文檔中相關(guān)度、詞在查詢關(guān)鍵字中的相關(guān)度以及詞的權(quán)重。BM25里的一些參數(shù)是經(jīng)驗總結(jié)得到的,后面我會繼續(xù)介紹BM25的變種以及和其他文檔信息(非文字)結(jié)合起來的應(yīng)用。
參考
BM25 算法淺析
搜索之 BM25 和 BM25F 模型
經(jīng)典搜索核心算法:BM25 及其變種
信息檢索導(dǎo)論
