第四部分:完全分布式安裝
完全布式環境部署Hadoop
完全分部式是真正利用多臺Linux主機來進行部署Hadoop,對Linux機器集群進行規劃,使得Hadoop各個模塊分別部署在不同的多臺機器上。
一、環境準備
1、 克隆虛擬機
Vmware左側選中要克隆的機器,這里對原有的hadoop01機器進行克隆,虛擬機菜單中,選中管理菜單下的克隆命令。
選擇“創建完整克隆”,虛擬機名稱為hadoop03,選擇虛擬機文件保存路徑,進行克隆。
再次克隆一個名為hadoop04的虛擬機。
2、 配置Hostname
BigData02配置hostname為 hadoop03
BigData03配置hostname為 hadoop03
3、 配置hosts
BigData01、BigData02、BigData03三臺機器hosts都配置為:
[hadoop@hadoop01 hadoop]# vim /etc/hosts
192.168.100.10 hadoop01
192.168.100.12 hadoop03
192.168.100.13 hadoop04
4、 配置Windows上的SSH客戶端
在本地Windows中的SSH客戶端上添加對hadoop03、hadoop04機器的SSH鏈接。
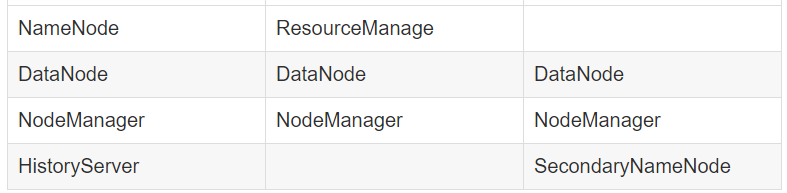
二、服務器功能規劃
| hadoop01 | hadoop03 | hadoop04 |
|---|
三、在第一臺機器上安裝新的Hadoop
為了和之前hadoop01機器上安裝偽分布式Hadoop區分開來,我們將hadoop01上的Hadoop服務都停止掉,然后在一個新的目錄/opt/modules/app下安裝另外一個Hadoop。
我們采用先在第一臺機器上解壓、配置Hadoop,然后再分發到其他兩臺機器上的方式來安裝集群。
6、 解壓Hadoop目錄:
[hadoop@hadoop01 modules]# tar -zvxf /opt/modules/hadoop-2.5.0.tar.gz
7、 配置Hadoop JDK路徑修改hadoop-env.sh、mapred-env.sh、yarn-env.sh文件中的JDK路徑:
export JAVA_HOME="/opt/modules/app/jdk1.8"
8、 配置core-site.xml
[hadoop@hadoop01 hadoop]# vim etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata-senior01.chybinmy.com:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/modules/app/hadoop-2.5.0/data/tmp</value>
</property>
</configuration>
fs.defaultFS為NameNode的地址。
hadoop.tmp.dir為hadoop臨時目錄的地址,默認情況下,NameNode和DataNode的數據文件都會存在這個目錄下的對應子目錄下。應該保證此目錄是存在的,如果不存在,先創建。
9、 配置hdfs-site.xml
[hadoop@hadoop01 hadoop]# vim etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop03:50090</value>
</property>
</configuration>
dfs.namenode.secondary.http-address是指定secondaryNameNode的http訪問地址和端口號,因為在規劃中,我們將BigData03規劃為SecondaryNameNode服務器。
所以這里設置為:bigdata-senior03.chybinmy.com:50090
10、 配置slaves
[hadoop@hadoop01 hadoop]# vim etc/hadoop/slaves
hadoop01
hadoop03
hadoop04
slaves文件是指定HDFS上有哪些DataNode節點。
11、 配置yarn-site.xml
[hadoop@ hadoop01 hadoop]# vim etc/hadoop/yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata-senior02.chybinmy.com</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>106800</value>
</property>
根據規劃yarn.resourcemanager.hostname這個指定resourcemanager服務器指向bigdata-senior02.chybinmy.com。
yarn.log-aggregation-enable是配置是否啟用日志聚集功能。
yarn.log-aggregation.retain-seconds是配置聚集的日志在HDFS上最多保存多長時間。
12、 配置mapred-site.xml
從mapred-site.xml.template復制一個mapred-site.xml文件。
[hadoop@hadoop01 hadoop]# cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>bigdata-senior01.chybinmy.com:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>bigdata-senior01.chybinmy.com:19888</value>
</property>
</configuration>
mapreduce.framework.name設置mapreduce任務運行在yarn上。
mapreduce.jobhistory.address是設置mapreduce的歷史服務器安裝在BigData01機器上。
mapreduce.jobhistory.webapp.address是設置歷史服務器的web頁面地址和端口號。
四、設置SSH無密碼登錄
Hadoop集群中的各個機器間會相互地通過SSH訪問,每次訪問都輸入密碼是不現實的,所以要配置各個機器間的
SSH是無密碼登錄的。
1、 在 hadoop01上生成公鑰
[hadoop@ hadoop01 hadoop]# ssh-keygen -t rsa
一路回車,都設置為默認值,然后再當前用戶的Home目錄下的.ssh目錄中會生成公鑰文件(id_rsa.pub)和私鑰文件(id_rsa)。
2、 分發公鑰
yum -y install openssh-server openssh-clients
[hadoop@ hadoop01 hadoop]# ssh-copy-id hadoop01
[hadoop@ hadoop01 hadoop]# ssh-copy-id hadoop03
[hadoop@ hadoop01 hadoop]# ssh-copy-id hadoop04
3、 設置hadoop03、hadoop04到其他機器的無密鑰登錄
同樣的在hadoop03、hadoop04上生成公鑰和私鑰后,將公鑰分發到三臺機器上。
二十九、分發Hadoop文件
1、 首先在其他兩臺機器上創建存放Hadoop的目錄
[hadoop@hadoop03 ~]# mkdir /opt/modules/app
[hadoop@hadoop04 ~]# mkdir /opt/modules/app
2、 通過Scp分發
Hadoop根目錄下的share/doc目錄是存放的hadoop的文檔,文件相當大,建議在分發之前將這個目錄刪除掉,可以節省硬盤空間并能提高分發的速度。
doc目錄大小有1.6G。
[hadoop@hadoop01 hadoop]# scp -r /opt/modules/app/hadoop/ hadoop03:/opt/modules/app
[hadoop@hadoop01 hadoop]# scp -r /opt/modules/app/hadoop/ hadoop04:/opt/modules/app
五、格式NameNode
在NameNode機器上執行格式化:
[hadoop@hadoop01 hadoop]# /opt/modules/app/hadoop/bin/hdfs namenode –format
注意:
如果需要重新格式化NameNode,需要先將原來NameNode和DataNode下的文件全部刪除,不然會報錯,NameNode和DataNode所在目錄是在core-site.xml中hadoop.tmp.dir、dfs.namenode.name.dir、dfs.datanode.data.dir屬性配置的。
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/data/tmp</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data</value>
</property>
因為每次格式化,默認是創建一個集群ID,并寫入NameNode和DataNode的VERSION文件中(VERSION文件所在目錄為dfs/name/current 和 dfs/data/current),重新格式化時,默認會生成一個新的集群ID,如果不刪除原來的目錄,會導致namenode中的VERSION文件中是新的集群ID,而DataNode中是舊的集群ID,不一致時會報錯。
另一種方法是格式化時指定集群ID參數,指定為舊的集群ID。
六、啟動集群
1、 啟動HDFS
[hadoop@hadoop hadoop]# /opt/modules/app/hadoop/sbin/start-dfs.sh
enter image description here
2、 啟動YARN
[hadoop@hadoop hadoop]# /opt/modules/app/hadoop/sbin/start-yarn.sh
在hadoop04上啟動ResourceManager:
[hadoop@hadoop04 hadoop]# sbin/yarn-daemon.sh start resourcemanager
enter image description here
3、 啟動日志服務器
因為我們規劃的是在hadoop04服務器上運行MapReduce日志服務,所以要在hadoop04上啟動。
[hadoop@hadoop04 ~]# /opt/modules/app/hadoop/sbin/mr-jobhistory-daemon.sh start historyserver
[hadoop@hadoop04 ~]# jps
3570 Jps
3537 JobHistoryServer
3310 SecondaryNameNode
3213 DataNode
3392 NodeManager
4、 查看HDFS Web頁面
http://hadoop01.chybinmy.com:50070/
5、 查看YARN Web 頁面
http://hadoop03:8088/cluster
七、測試Job
我們這里用hadoop自帶的wordcount例子來在本地模式下測試跑mapreduce。
1、 準備mapreduce輸入文件wc.input
[hadoop@hadoop01 modules]# cat /opt/data/wc.input
hadoop mapreduce hive
hbase spark storm
sqoop hadoop hive
spark hadoop
2、 在HDFS創建輸入目錄input
[hadoop@hadoop01 hadoop]# bin/hdfs dfs -mkdir /input
3、 將wc.input上傳到HDFS
[hadoop@hadoop01 hadoop]# bin/hdfs dfs -put /opt/data/wc.input /input/wc.input
4、 運行hadoop自帶的mapreduce Demo
[hadoop@hadoop01 hadoop]# bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /input/wc.input /output
5、 查看輸出文件
[hadoop@hadoop01 hadoop]# bin/hdfs dfs -ls /output
Found 2 items
-rw-r--r-- 3 hadoop supergroup 0 2016-07-14 16:36 /output/_SUCCESS
-rw-r--r-- 3 hadoop supergroup 60 2016-07-14 16:36 /output/part-r-00000
