Streams
- 原文鏈接: Streams
- 原文作者: shekhargulati
- 譯者: leege100
- 狀態: 完成
在第二章中,我們學習到了lambda表達式允許我們在不創建新類的情況下傳遞行為,從而幫助我們寫出干凈簡潔的代碼。lambda表達式是一種簡單的語法結構,它通過使用函數式接口來幫助開發者簡單明了的傳遞意圖。當采用lambda表達式的設計思維來設計API時,lambda表達式的強大就會得到體現,比如我們在第二節討論的使用函數式接口編程的APIlambdas chapter。
Stream是java8引入的一個重度使用lambda表達式的API。Stream使用一種類似用SQL語句從數據庫查詢數據的直觀方式來提供一種對Java集合運算和表達的高階抽象。直觀意味著開發者在寫代碼時只需關注他們想要的結果是什么而無需關注實現結果的具體方式。這一章節中,我們將介紹為什么我們需要一種新的數據處理API、Collection和Stream的不同之處以及如何將StreamAPI應用到我們的編碼中。
本節的代碼見 ch03 package.
為什么我們需要一種新的數據處理抽象概念?
在我看來,主要有兩點:
- Collection API 不能提供更高階的結構來查詢數據,因而開發者不得不為實現大多數瑣碎的任務而寫一大堆樣板代碼。
2、對集合數據的并行處理有一定的限制,如何使用Java語言的并發結構、如何高效的處理數據以及如何高效的并發都需要由程序員自己來思考和實現。
Java 8之前的數據處理
閱讀下面這一段代碼,猜猜看它是拿來做什么的。
public class Example1_Java7 {
public static void main(String[] args) {
List<Task> tasks = getTasks();
List<Task> readingTasks = new ArrayList<>();
for (Task task : tasks) {
if (task.getType() == TaskType.READING) {
readingTasks.add(task);
}
}
Collections.sort(readingTasks, new Comparator<Task>() {
@Override
public int compare(Task t1, Task t2) {
return t1.getTitle().length() - t2.getTitle().length();
}
});
for (Task readingTask : readingTasks) {
System.out.println(readingTask.getTitle());
}
}
}
上面這段代碼是用來按照字符串長度的排序打印所有READING類型的task的title。所有Java開發者每天都會寫這樣的代碼,為了寫出這樣一個簡單的程序,我們不得不寫下15行Java代碼。然而上面這段代碼最大的問題不在于其代碼長度,而在于不能清晰傳達開發者的意圖:過濾出所有READING的task、按照字符串的長度排序然后生成一個String類型的List。
Java8中的數據處理
可以像下面這段代碼這樣,使用java8中的Stream API來實現與上面代碼同等的效果。
public class Example1_Stream {
public static void main(String[] args) {
List<Task> tasks = getTasks();
List<String> readingTasks = tasks.stream()
.filter(task -> task.getType() == TaskType.READING)
.sorted((t1, t2) -> t1.getTitle().length() - t2.getTitle().length())
.map(Task::getTitle)
.collect(Collectors.toList());
readingTasks.forEach(System.out::println);
}
}
上面這段代碼中,形成了一個由多個stream操作組成的管道。
stream() - 通過在類似上面
tasksList<Task>的集合源上調用stream()方法來創建一個stream的管道。filter(Predicate<T>) - 這個操作用來提取stream中匹配predicate定義規則的元素。如果你有一個stream,你可以在它上面調用零次或者多次間斷的操作。lambda表達式
task -> task.getType() == TaskType.READING定義了一個用來過濾出所有READING的task的規則。sorted(Comparator<T>): This operation returns a stream consisting of all the stream elements sorted by the Comparator defined by lambda expression i.e. in the example shown above.此操作返回一個stream,此stream由所有按照lambda表達式定義的Comparator來排序后的stream元素組成,在上面代碼中排序的表達式是(t1, t2) -> t1.getTitle().length() - t2.getTitle().length().
map(Function<T,R>): 此操作返回一個stream,該stream的每個元素來自原stream的每個元素通過Function<T,R>處理后得到的結果。
collect(toList()) -此操作把上面對stream進行各種操作后的結果裝進一個list中。
為什么說Java8更好
In my opinion Java 8 code is better because of following reasons:
在我看來,Java8的代碼更好主要有以下幾點原因:
Java8代碼能夠清晰地表達開發者對數據過濾、排序等操作的意圖。
通過使用Stream API格式的更高抽象,開發者表達他們所想要的是什么而不是怎么去得到這些結果。
Stream API為數據處理提供一種統一的語言,使得開發者在談論數據處理時有共同的詞匯。當兩個開發者討論
filter函數時,你都會明白他們都是在進行一個數據過濾操作。開發者不再需要為實現數據處理而寫的各種樣板代碼,也不再需要為loop代碼或者臨時集合來儲存數據的冗余代碼,Stream API會處理這一切。
Stream不會修改潛在的集合,它是非交換的。
Stream是什么
Stream是一個在某些數據上的抽象視圖。比如,Stream可以是一個list或者文件中的幾行或者其他任意的一個元素序列的視圖。Stream API提供可以順序表現或者并行表現的操作總和。開發者需要明白一點,Stream是一種更高階的抽象概念,而不是一種數據結構。Stream不會儲存數據Stream天生就很懶,只有在被使用到時才會執行計算。它允許我們產生無限的數據流(stream of data)。在Java8中,你可以像下面這樣,非常輕松的寫出一個無限制生成特定標識符的代碼:
public static void main(String[] args) {
Stream<String> uuidStream = Stream.generate(() -> UUID.randomUUID().toString());
}
在Stream接口中有諸如of、generate、iterate等多種靜態工廠方法可以用來創建stream實例。上面提到的generate方法帶有一個Supplier,Supplier是一個可以用來描述一個不需要任何輸入且會產生一個值的函數的函數式接口,我們向generate方法中傳遞一個supplier,當它被調用時會生成一個特定標識符。
Supplier<String> uuids = () -> UUID.randomUUID().toString()
運行上面這段代碼,什么都不會發生,因為Stream是懶加載的,直到被使用時才會執行。如果我們改成如下這段代碼,我們就會在控制臺看到打印出來的UUID。這段程序會一直執行下去。
public static void main(String[] args) {
Stream<String> uuidStream = Stream.generate(() -> UUID.randomUUID().toString());
uuidStream.forEach(System.out::println);
}
Java8運行開發者通過在一個Collection上調用stream方法來創建Stream。Stream支持數據處理操作,從而開發者可以使用更高階的數據處理結構來表達運算。
Collection vs Stream
下面這張表闡述了Collection和Stream的不同之處

下面我們來探討內迭代(internal iteration)和外迭代(external iteration)的區別,以及懶賦值的概念。
外迭代(External iteration) vs (內迭代)internal iterationvs
上面談到的Java8 Stream API代碼和Collection API代碼的區別在于由誰來控制迭代,是迭代器本身還是開發者。Stream API僅僅提供他們想要實現的操作,然后迭代器把這些操作應用到潛在Collection的每個元素中去。當對潛在的Collection進行的迭代操作是由迭代器本身控制時,就叫著內迭代;反之,當迭代操作是由開發者控制時,就叫著外迭代。Collection API中for-each結構的使用就是一個外迭代的例子。
有人會說,在Collection API中我們也不需要對潛在的迭代器進行操作,因為for-each結構已經替我們處理得很好了,但是for-each結構其實不過是一種iterator API的語法糖罷了。for-each盡管很簡單,但是它有一些缺點 -- 1)只有固有順序 2)容易寫出生硬的命令式代碼(imperative code) 3)難以并行。
Lazy evaluation懶加載
stream表達式在被終極操作方法調用之前不會被賦值計算。Stream API中的大多數操作會返回一個Stream。這些操作不會做任何的執行操作,它們只會構建這個管道。看著下面這段代碼,預測一下它的輸出會是什么。
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
Stream<Integer> stream = numbers.stream().map(n -> n / 0).filter(n -> n % 2 == 0);
上面這段代碼中,我們將stream元素中的數字除以0,我們也許會認為這段代碼在運行時會拋出ArithmeticExceptin異常,而事實上不會。因為stream表達式只有在有終極操作被調用時才會被執行運算。如果我們為上面的stream加上終極操作,stream就會被執行并拋出異常。
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
Stream<Integer> stream = numbers.stream().map(n -> n / 0).filter(n -> n % 2 == 0);
stream.collect(toList());
我們會得到如下的stack trace:
Exception in thread "main" java.lang.ArithmeticException: / by zero
at org._7dayswithx.java8.day2.EagerEvaluationExample.lambda$main$0(EagerEvaluationExample.java:13)
at org._7dayswithx.java8.day2.EagerEvaluationExample$$Lambda$1/1915318863.apply(Unknown Source)
at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193)
at java.util.Spliterators$ArraySpliterator.forEachRemaining(Spliterators.java:948)
at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:512)
at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:502)
at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708)
at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234)
at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:499)
使用Stream API
Stream API提供了一大堆開發者可以用來從集合中查詢數據的操作,這些操作分為兩種--過渡操作和終極操作。
過渡操作從已存在的stream上產生另一個新的stream的函數,比如filter,map, sorted,等。
終極操作從stream上產生一個非stream結果的函數,如collect(toList()) , forEach, count等。
過渡操作允許開發者構建在調用終極操作時才執行的管道。下面是Stream API的部分函數列表:
<a >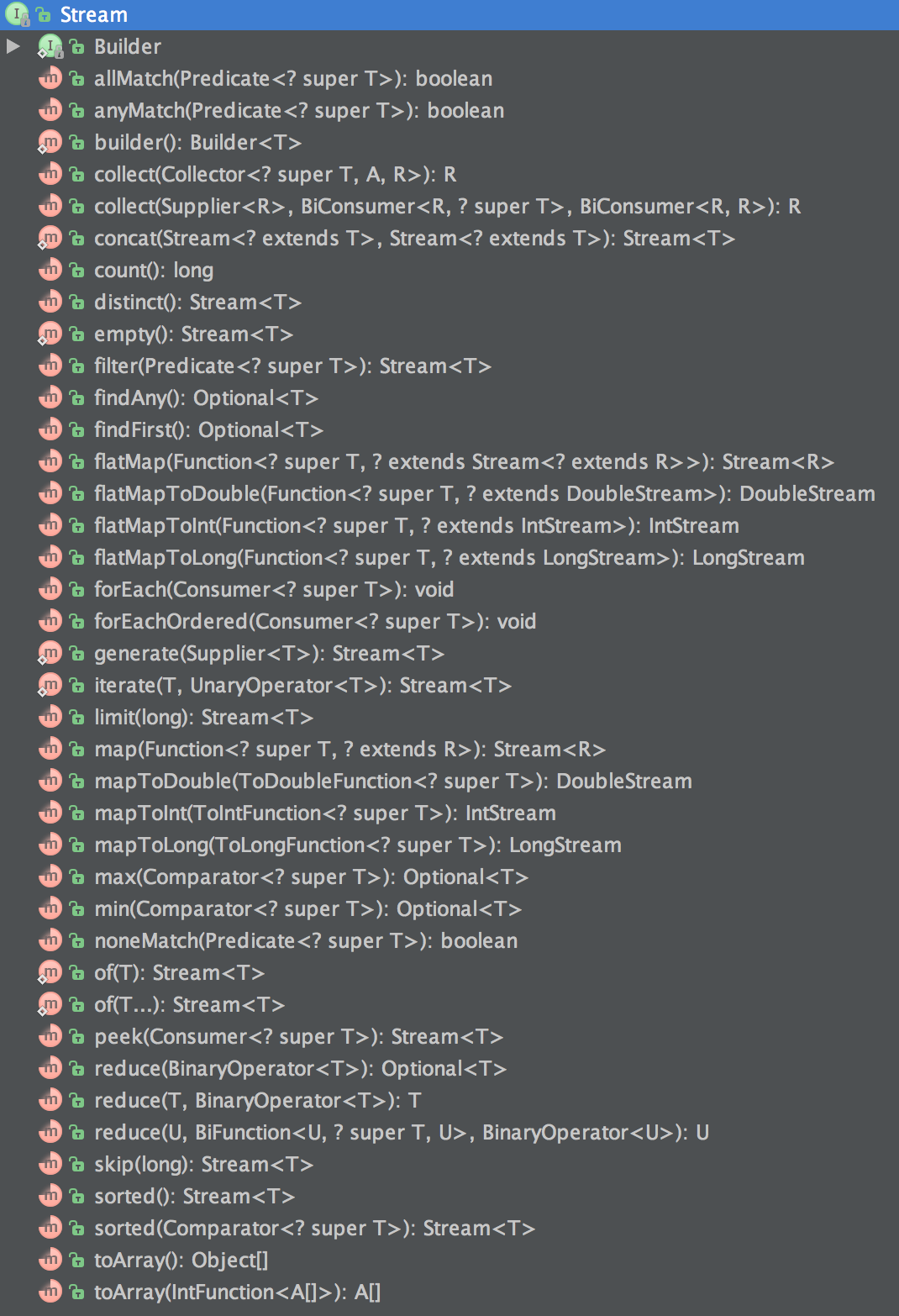
</a>
示例類
在本教程中,我們將會用Task管理類來解釋這些概念。例子中,有一個叫Task的類,它是一個由用戶來表現的類,其定義如下:
import java.time.LocalDate;
import java.util.*;
public class Task {
private final String id;
private final String title;
private final TaskType type;
private final LocalDate createdOn;
private boolean done = false;
private Set<String> tags = new HashSet<>();
private LocalDate dueOn;
// removed constructor, getter, and setter for brevity
}
例子中的數據集如下,在整個Stream API例子中我們都會用到它。
Task task1 = new Task("Read Version Control with Git book", TaskType.READING, LocalDate.of(2015, Month.JULY, 1)).addTag("git").addTag("reading").addTag("books");
Task task2 = new Task("Read Java 8 Lambdas book", TaskType.READING, LocalDate.of(2015, Month.JULY, 2)).addTag("java8").addTag("reading").addTag("books");
Task task3 = new Task("Write a mobile application to store my tasks", TaskType.CODING, LocalDate.of(2015, Month.JULY, 3)).addTag("coding").addTag("mobile");
Task task4 = new Task("Write a blog on Java 8 Streams", TaskType.WRITING, LocalDate.of(2015, Month.JULY, 4)).addTag("blogging").addTag("writing").addTag("streams");
Task task5 = new Task("Read Domain Driven Design book", TaskType.READING, LocalDate.of(2015, Month.JULY, 5)).addTag("ddd").addTag("books").addTag("reading");
List<Task> tasks = Arrays.asList(task1, task2, task3, task4, task5);
本章節暫不討論Java8的Data Time API,這里我們就把它當著一個普通的日期的API。
Example 1: 找出所有READING Task的標題,并按照它們的創建時間排序。
第一個例子我們將要實現的是,從Task列表中找出所有正在閱讀的任務的標題,并根據它們的創建時間排序。我們要做的操作如下:
- 過濾出所有TaskType為READING的Task。
- 按照創建時間對task進行排序。
- 獲取每個task的title。
- 將得到的這些title裝進一個List中。
上面的四個操作步驟可以非常簡單的翻譯成下面這段代碼:
private static List<String> allReadingTasks(List<Task> tasks) {
List<String> readingTaskTitles = tasks.stream().
filter(task -> task.getType() == TaskType.READING).
sorted((t1, t2) -> t1.getCreatedOn().compareTo(t2.getCreatedOn())).
map(task -> task.getTitle()).
collect(Collectors.toList());
return readingTaskTitles;
}
在上面的代碼中,我們使用了Stream API中如下的一些方法:
filter:允許開發者定義一個判斷規則來從潛在的stream中提取符合此規則的部分元素。規則task -> task.getType() == TaskType.READING意為從stream中選取所有TaskType 為READING的元素。
sorted: 允許開發者定義一個比較器來排序stream。上例中,我們根據創建時間來排序,其中的lambda表達式(t1, t2) -> t1.getCreatedOn().compareTo(t2.getCreatedOn())就對函數式接口Comparator中的
compare函數進行了實現。map: 需要一個實現了能夠將一個stream轉換成另一個stream的
Function<? super T, ? extends R>的lambda表達式作為參數,Function<? super T, ? extends R>接口能夠將一個stream轉換為另一個stream。lambda表達式task -> task.getTitle()將一個task轉化為標題。collect(toList()) 這是一個終極操作,它將所有READING的Task的標題的裝進一個list中。
我們可以通過使用Comparator接口的comparing方法和方法引用來將上面的代碼簡化成如下代碼:
public List<String> allReadingTasks(List<Task> tasks) {
return tasks.stream().
filter(task -> task.getType() == TaskType.READING).
sorted(Comparator.comparing(Task::getCreatedOn)).
map(Task::getTitle).
collect(Collectors.toList());
}
從Java8開始,接口可以含有通過靜態和默認方法來實現方法,在ch01已經介紹過了。
方法引用Task::getCreatedOn是由Function<Task,LocalDate>而來的。
上面代碼中,我們使用了Comparator接口中的靜態幫助方法comparing,此方法需要接收一個用來提取Comparable的Function作為參數,返回一個通過key進行比較的Comparator。方法引用Task::getCreatedOn 是由 Function<Task, LocalDate>而來的.
我們可以像如下代碼這樣,使用函數組合,通過在Comparator上調用reversed()方法,來非常輕松的顛倒排序。
public List<String> allReadingTasksSortedByCreatedOnDesc(List<Task> tasks) {
return tasks.stream().
filter(task -> task.getType() == TaskType.READING).
sorted(Comparator.comparing(Task::getCreatedOn).reversed()).
map(Task::getTitle).
collect(Collectors.toList());
}
Example 2: 去除重復的tasks
假設我們有一個有很多重復task的數據集,可以像如下代碼這樣通過調用distinct方法來輕松的去除stream中的重復的元素:
public List<Task> allDistinctTasks(List<Task> tasks) {
return tasks.stream().distinct().collect(Collectors.toList());
}
distinct()方法把一個stream轉換成一個不含重復元素的stream,它通過對象的equals方法來判斷對象是否相等。根據對象相等方法的判定,如果兩個對象相等就意味著有重復,它就會從結果stream中移除。
Example 3: 根據創建時間排序,找出前5個處于reading狀態的task
limit方法可以用來把結果集限定在一個給定的數字。limit是一個短路操作,意味著它不會為了得到結果而去運算所有元素。
public List<String> topN(List<Task> tasks, int n){
return tasks.stream().
filter(task -> task.getType() == TaskType.READING).
sorted(comparing(Task::getCreatedOn)).
map(Task::getTitle).
limit(n).
collect(toList());
}
可以像如下代碼這樣,同時使用skip方法和limit方法來創建某一頁。
// page starts from 0. So to view a second page `page` will be 1 and n will be 5.
//page從0開始,所以要查看第二頁的話,`page`應該為1,n應該為5
List<String> readingTaskTitles = tasks.stream().
filter(task -> task.getType() == TaskType.READING).
sorted(comparing(Task::getCreatedOn).reversed()).
map(Task::getTitle).
skip(page * n).
limit(n).
collect(toList());
Example 4:統計狀態為reading的task的數量
要得到所有正處于reading的task的數量,我們可以在stream中使用count方法來獲得,這個方法是一個終極方法。
public long countAllReadingTasks(List<Task> tasks) {
return tasks.stream().
filter(task -> task.getType() == TaskType.READING).
count();
}
Example 5: 非重復的列出所有task中的全部標簽
要找出不重復的標簽,我們需要下面幾個步驟
- 獲取每個task中的標簽。
- 把所有的標簽放到一個stream中。
- 刪除重復的標簽。
- 把最終結果裝進一個列表中。
第一步和第二步可以通過在stream上調用flatMap來得到。flatMap操作把通過調用task.getTags().stream得到的各個stream合成到一個stream。一旦我們把所有的tag放到一個stream中,我們就可以通過調用distinct方法來得到非重復的tag。
private static List<String> allDistinctTags(List<Task> tasks) {
return tasks.stream().flatMap(task -> task.getTags().stream()).distinct().collect(toList());
}
Example 6: 檢查是否所有reading的task都有book標簽
Stream API有一些可以用來檢測數據集中是否含有某個給定屬性的方法,allMatch,anyMatch,noneMatch,findFirst,findAny。要判斷是否所有狀態為reading的task的title中都包含books標簽,可以用如下代碼來實現:
public boolean isAllReadingTasksWithTagBooks(List<Task> tasks) {
return tasks.stream().
filter(task -> task.getType() == TaskType.READING).
allMatch(task -> task.getTags().contains("books"));
}
要判斷所有reading的task中是否存在一個task包含java8標簽,可以通過anyMatch來實現,代碼如下:
public boolean isAnyReadingTasksWithTagJava8(List<Task> tasks) {
return tasks.stream().
filter(task -> task.getType() == TaskType.READING).
anyMatch(task -> task.getTags().contains("java8"));
}
Example 7: 創建一個所有title的總覽
當你想要創建一個所有title的總覽時就可以使用reduce操作,reduce能夠把stream變成成一個值。reduce函數接受一個可以用來連接stream中所有元素的lambda表達式。
public String joinAllTaskTitles(List<Task> tasks) {
return tasks.stream().
map(Task::getTitle).
reduce((first, second) -> first + " *** " + second).
get();
}
Example 8: 基本類型stream的操作
除了常見的基于對象的stream,Java8對諸如int,long,double等基本類型也提供了特定的stream。下面一起來看一些基本類型的stream的例子。
要創建一個值區間,可以調用range方法。range方法創建一個值為0到9的stream,不包含10。
IntStream.range(0, 10).forEach(System.out::println);
rangeClosed方法允許我們創建一個包含上限值的stream。因此,下面的代碼會產生一個從1到10的stream。
IntStream.rangeClosed(1, 10).forEach(System.out::println);
還可以像下面這樣,通過在基本類型的stream上使用iterate方法來創建無限的stream:
LongStream infiniteStream = LongStream.iterate(1, el -> el + 1);
要從一個無限的stream中過濾出所有偶數,可以用如下代碼來實現:
infiniteStream.filter(el -> el % 2 == 0).forEach(System.out::println);
可以通過使用limit操作來現在結果stream的個數,代碼如下:
We can limit the resulting stream by using the limit operation as shown below.
infiniteStream.filter(el -> el % 2 == 0).limit(100).forEach(System.out::println);
Example 9: 為數組創建stream
可以像如下代碼這樣,通過調用Arrays類的靜態方法stream來把為數組建立stream:
String[] tags = {"java", "git", "lambdas", "machine-learning"};
Arrays.stream(tags).map(String::toUpperCase).forEach(System.out::println);
還可以像如下這樣,根據數組中特定起始下標和結束下標來創建stream。這里的起始下標包括在內,而結束下標不包含在內。
Arrays.stream(tags, 1, 3).map(String::toUpperCase).forEach(System.out::println);
Parallel Streams并發的stream
使用Stream有一個優勢在于,由于stream采用內部迭代,所以java庫能夠有效的管理處理并發。可以在一個stream上調用parallel方法來使一個stream處于并行。parallel方法的底層實現基于JDK7中引入的fork-joinAPI。默認情況下,它會產生與機器CPU數量相等的線程。下面的代碼中,我們根據處理它們的線程來對將數字分組。在第4節中將學習collect和groupingBy函數,現在暫時理解為它可以根據一個key來對元素進行分組。
public class ParallelStreamExample {
public static void main(String[] args) {
Map<String, List<Integer>> numbersPerThread = IntStream.rangeClosed(1, 160)
.parallel()
.boxed()
.collect(groupingBy(i -> Thread.currentThread().getName()));
numbersPerThread.forEach((k, v) -> System.out.println(String.format("%s >> %s", k, v)));
}
}
在我的機器上,打印的結果如下:
ForkJoinPool.commonPool-worker-7 >> [46, 47, 48, 49, 50]
ForkJoinPool.commonPool-worker-1 >> [41, 42, 43, 44, 45, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130]
ForkJoinPool.commonPool-worker-2 >> [146, 147, 148, 149, 150]
main >> [106, 107, 108, 109, 110]
ForkJoinPool.commonPool-worker-5 >> [71, 72, 73, 74, 75]
ForkJoinPool.commonPool-worker-6 >> [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 151, 152, 153, 154, 155, 156, 157, 158, 159, 160]
ForkJoinPool.commonPool-worker-3 >> [21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 76, 77, 78, 79, 80]
ForkJoinPool.commonPool-worker-4 >> [91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145]
并不是每個工作的線程都處理相等數量的數字,可以通過更改系統屬性來控制fork-join線程池的數量System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism", "2")。
另外一個會用到parallel操作的例子是,當你像下面這樣要處理一個URL的列表時:
String[] urls = {"https://www.google.co.in/", "https://twitter.com/", "http://www.facebook.com/"};
Arrays.stream(urls).parallel().map(url -> getUrlContent(url)).forEach(System.out::println);
如果你想更好的掌握什么時候應該使用并發的stream,推薦你閱讀由Doug Lea和其他幾位Java大牛寫的文章http://gee.cs.oswego.edu/dl/html/StreamParallelGuidance.html。
