對于python軟件爬取網頁數據,一般采用BeautifulSoup庫或者Xpath技術來解析html,然后尋找爬取對象的網頁路徑來定位所需數據,進而利用循環條件來不斷獲取數據。另外,也可以使用Scrapy框架來爬取。對于上述軟件包或庫,在進行網頁爬蟲時需要安裝相關庫并導入,而Scrapy框架目前windows系統下python3軟件還不一定安裝不了。在這里介紹一種單純使用find()函數來爬取數據的方法,它不需要安裝和導入上述Python庫,僅僅依靠讀取網頁之后形成的代碼文檔,通過定位爬取對象的位置及范圍,來獲得所需數據。在這里為了簡單介紹一下這一方法,本文以最近上映大片——張藝謀導演的《長城》電影,其豆瓣短評的第一頁為例(長城 短評**),爬取每一個短評。
import urllib.request
req = urllib.request.urlopen('https://movie.douban.com/subject/6982558/comments?sort=new_score&status=P')
txt = req.read().decode('utf-8')
print(txt)```
通過打印txt,可以看到每個短評處于<p class=""> </p>之間,那么就可以使用find函數來找到這兩個參數第一次出現的開頭位置。
words = txt.find(r'p class=""')
wordsend = txt.find(r'/p',words) #縮小范圍,在words位置范圍內尋找/p```
其中,wordsend就在從第一個words出現的位置,這也能做可以縮小搜尋范圍。
接下來就是存儲第一個短評,并形成循環將該網頁的其他短評也依次找到并存儲。
com=[]
i =0
while words !=-1 and wordsend !=-1 :
com1 = txt[words +11:wordsend-1].split(' ')[0].strip()#將第一個評論儲存起來
com.append(com1)
words = txt.find(r'p class=""',wordsend) #從上一個wordsend開始尋找下一個p class
wordsend = txt.find(r'/p', words)
i = i + 1
else:
print('the end!')
print(com)```
在這里需要特別說明的就是,com1 = txt[words +11:wordsend-1].split(' ')[0].strip(),其中
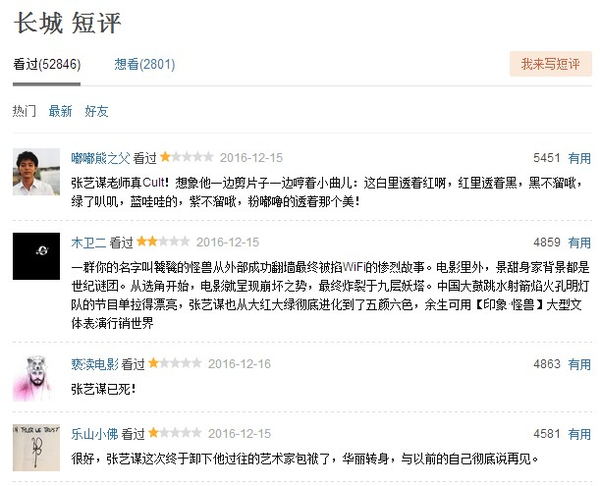
txt[words +11:wordsend-1]就是網頁txt文檔中第一條短評的前后位置范圍找到再提取出來,其中短評最開始的位置就是words變量中p class=""的p開始數字符串,第11位,結束位置則是wordsend中/p往前一位,如圖:
但是如果單純依靠strip()來去除標點符號等,還會出現錯誤,比如有人用手機發帖,在<p class=""> </p>之間還會有如下字符:
因此,在這里先用split截取第一個字段,再strip().
最終打印,得到第一頁所有短評文字。對于多網頁的抓取則可以再使用while循環,結合每個網頁的特點,運用page = page + 1來不斷抓取。在此基礎上,設置一定的停止條件,就爬到了對《長城》這一電影所有短評。然后我們就可以進行分析大家對《長城》這部電影的關注點、吐糟點等等,采用詞頻分析,文本挖掘以及詞云等來進行數據分析。