前言
? 本資料整理了高光譜遙感圖像概念定義、分析處理與分類識別的基本知識。第一部分介紹高光譜圖像的一般性原理和知識,第二部分介紹了高光譜圖像的噪聲問題;第三部分介紹高光譜圖像數(shù)據(jù)冗余問題以及數(shù)據(jù)降維解決冗余的方法;第四部分介紹高光譜圖像的混合像元問題,對光譜解混做了一定介紹;第五部分和第六部分分別介紹了高光譜圖像的監(jiān)督分類和分監(jiān)督分類的特點、流程和常用算法。
1.基本介紹
高光譜遙感(Hyperspectral remote sensing) 是將成像技術(shù)和光譜技術(shù)相結(jié)合的多維信息獲取技術(shù),同時探測目標(biāo)的二維集合空間與一維光譜信息,獲取高光譜分辨率的連續(xù)、窄波段圖像數(shù)據(jù)。
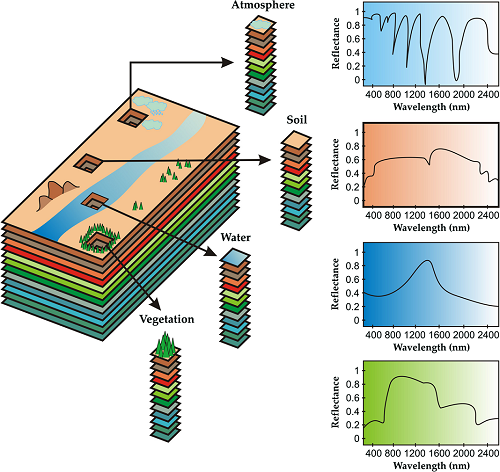
高光譜圖像與高分辨率圖像、多光譜圖像不同。
高光譜識別優(yōu)勢:
光譜分辨率高、波段眾多,能夠獲取地物幾乎連續(xù)的光譜特征曲線,并可以根據(jù)需要選擇或提取特定波段來突出目標(biāo)特征;
同一空間分辨率下,光譜覆蓋范圍更寬,能夠探測到地物更多對電磁波的響應(yīng)特征;
波段多,為波段之間的相互校正提供了便利;
定量化的連續(xù)光譜曲線數(shù)據(jù)為地物光譜機理模型引入圖像分類提供了條件;
包含豐富的輻射、空間和光譜信息,是多種信息的綜合載體。
高光譜在識別方面的困難:
- 數(shù)據(jù)量大,圖像包含幾十個到上百個波段,數(shù)據(jù)量是單波段遙感圖像的幾百倍;數(shù)據(jù)存在大量冗余,處理不當(dāng),反而會影響分類精度;
- 對高光譜圖像的分類一方面要求更高的光譜定標(biāo)和反射率轉(zhuǎn)換的精度,另一方面又因為成像機理復(fù)雜,數(shù)據(jù)量巨大而導(dǎo)致對圖像數(shù)據(jù)預(yù)處理困難,包括大氣矯正、幾何校正、光譜定標(biāo)和反射率轉(zhuǎn)換等;
- 波段多、波段間的相關(guān)性高,因此分類需要的訓(xùn)練樣本數(shù)目大大增多,往往因訓(xùn)練樣本不足導(dǎo)致得到的訓(xùn)練參數(shù)不可靠(維數(shù)災(zāi)難);
- 針對常規(guī)遙感的處理模型和方法不能滿足高光譜圖像分類的需要。主要問題之一是統(tǒng)計學(xué)分類模型的參數(shù)估計問題,其對光譜特征的選擇要求很高。
高光譜圖像分類中的Hughes 現(xiàn)象:
? Hughes現(xiàn)象:在機器學(xué)習(xí)問題中,需要在高維特征空間(每個特征都能夠取一系列可能值)的有限數(shù)據(jù)樣本中學(xué)習(xí)一種“自然狀態(tài)”(可能是無窮分布),要求有相當(dāng)數(shù)量的訓(xùn)練數(shù)據(jù)含有一些樣本組合。給定固定數(shù)量的訓(xùn)練樣本,其預(yù)測能力隨著維度的增加而減小。
? 在高光譜遙感圖像中,當(dāng)訓(xùn)練樣本數(shù)目有限時,分類精度隨著圖像波段數(shù)目的增加先增加,在到達一定極值后,分類精度隨這波段數(shù)目的增加而下降。
? 傳統(tǒng)遙感圖像分析是利用圖像空間信息,高光譜圖像分析的核心是光譜分析。高光譜的遙感數(shù)據(jù)是一個光譜圖像立方體,其最主要的特點將圖像空間維與光譜維信息合為一體,與單波段相比,多出了一維光譜信息。在獲取地表空間圖像同時,會得到每個像元對應(yīng)的地物光譜信息。
?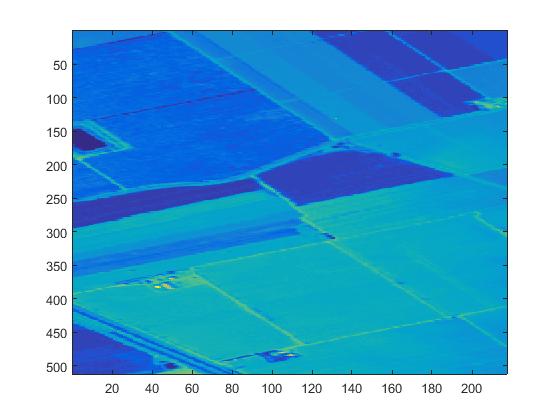
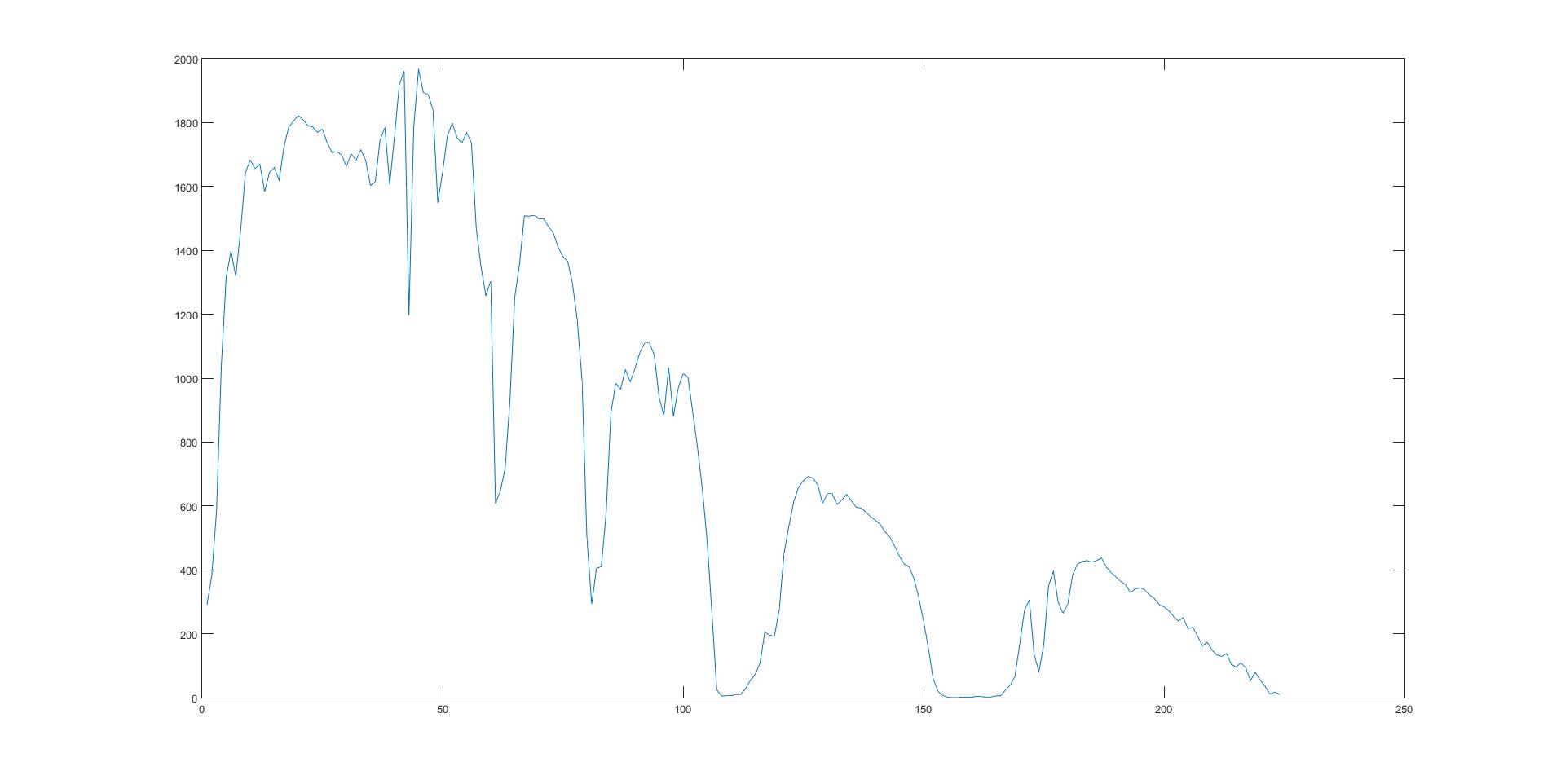
上圖分別是某波段的遙感影像圖和某像元的光譜特征圖。
2.高光譜數(shù)據(jù)噪聲處理
? 高光譜圖像精細光譜數(shù)據(jù)能夠充分反映地物光譜的細微特征。依據(jù)不同地物在光譜特征上的相對差異就可實現(xiàn)地物類別區(qū)分,實現(xiàn)目標(biāo)探測和精細分類。
? 但是,由于成像光譜儀波段通道很密而造成光成像能量不足,故相對全色圖而言,高光譜圖像的信噪比(SNR)提高比較困難。在圖像數(shù)據(jù)的獲取過程中,地物光譜特征在噪聲的影響下容易產(chǎn)生“失真”。另外由于高光譜數(shù)據(jù)量大,在精細分類過程中,往往需要對數(shù)據(jù)進行降維處理,而在降維過程中需要最大限度保留信號和壓縮噪聲,所以精確的噪聲評估很有必要。另外噪聲對精細分類的結(jié)果也有最直接影響。所以需要對高光譜數(shù)據(jù)進行噪聲評估。
? 主要的噪聲認(rèn)為是高斯白噪聲,分為加性噪聲和乘性噪聲。
? 噪聲評估主要有三種方法:實驗室法、暗電流法和圖像法。由于前兩種方法在實驗中難以實現(xiàn),廣泛應(yīng)用的是第三種——圖像法。
圖像法分為以下幾種:
-
均勻區(qū)域法(HA)
主要思想:從圖像中選取四個以上均勻區(qū)域,通過計算這些均勻區(qū)域標(biāo)準(zhǔn)差的平均值獲取圖像噪聲的估計值。
不足:需要人工進行均勻區(qū)域選擇,無法自動化;滿足條件的均勻區(qū)域在大部分遙感圖中并不存在;子區(qū)域噪聲估計并不能代表整幅圖像的噪聲。
-
地學(xué)統(tǒng)計法(GS)
主要思想:從圖像中選擇幾條均勻的窄條帶,通過對這些窄條帶的半方差函數(shù)的計算實現(xiàn)對圖像噪聲的估算。一定程度上利用了成像光譜數(shù)據(jù)的空間相關(guān)性。
不足:與均勻區(qū)域法相似。
-
局部均值與局部標(biāo)準(zhǔn)差法(LMLSD)
主要思想:假定圖像由大量均勻的小塊構(gòu)成,且噪聲以加性噪聲為主。使用局部均值和局部標(biāo)準(zhǔn)差的概念,將圖像分割為很多小塊,然后計算這些子塊的標(biāo)準(zhǔn)差作為局部噪聲大小,并選擇包含子塊數(shù)最多區(qū)間的局部標(biāo)準(zhǔn)差的平均值作為整個圖像的最佳噪聲估計。
不足:只對高斯白噪聲有效,對高斯隨機噪聲的圖像,信號被噪聲干擾。
-
空間/光譜維去相關(guān)法(SSDC)
主要思想:是一種專門針對高光譜圖像的噪聲評估方法,利用高光譜圖像空間維和光譜維存在高相關(guān)性的特點,通過多元線性回歸去除具有高相關(guān)性的信號,利用得到的殘差圖像對噪聲進行估算。
評價:該方法受地物覆蓋類型影響小,并且可以自動執(zhí)行,是目前較為穩(wěn)定的高光譜圖像噪聲評價方法。
3.高光譜圖像數(shù)據(jù)降維的常用方法
? 高光譜遙感圖像所具有的大量光譜波段為地物信息提取提供了極其豐富的信息,有利于更精細的地物分類,然而波段的增多也會導(dǎo)致信息的冗余和數(shù)據(jù)處理復(fù)雜性的提高。
數(shù)據(jù)降維滿足下面條件:盡可能保留數(shù)據(jù)的特征信息;去除數(shù)據(jù)冗余與相關(guān)性。
主要從特征選擇和特征提取兩方面進行降維處理。
3.1 特征選擇
特征選擇是光譜組合,即從原光譜波段數(shù)為$N$的波段中選擇$M$個波段$(N>M)$,可能的光譜組合數(shù)為
$$
\frac{N!}{M!(N-M)!}
$$
在這里可以采用Band Index 方法進行光譜波段選擇降維。
Band Index 方法:Hyperspectral 遙感圖像根據(jù)相關(guān)性分為$K$組(如shortwave light、visible light、near-infrared),設(shè)每個組中的波段數(shù)為 $n_l(l=1,2,\cdots , k)$。用$p {ij}$ 表示波段$i$ 與波段$j$的相關(guān)系數(shù) ,$\sigma_i$ 表示波段$i$的方差,$R_a$表示波段$i$與不同組其他波段相關(guān)系數(shù)的絕對值的和,$R_w$ 表示波段$i$與同組其他波段的相關(guān)系數(shù)的絕對值的均值,則有
$$
R_w = \frac{1}{n_l} \sum |p{ij}|
$$
從而波段$i$的Band Index 可表示為:
$$
P_i = \frac {\sigma_i}{R_a+R_w}
$$
通過觀察,我們知道隨著方差增大,波段包含的信息越多;隨著相關(guān)系數(shù)降低,波段的獨立性越高。
Band Index 是一個重要參數(shù),其反映了波段總體包含特征信息和相關(guān)性。
? 通過結(jié)合Band Index 和目標(biāo)物體有效的光譜范圍(effiective spectral scope of object),我們可以進行波段選擇,進而下一步識別分類。
3.2 特征提取
? 高光譜的數(shù)據(jù)降維技術(shù)是以圖像特征提取為目的,利用低維數(shù)據(jù)來有效地表達高維數(shù)據(jù)的特征,同時也壓縮了數(shù)據(jù)量,更有利于信息的快速提取。數(shù)據(jù)降維包含的內(nèi)容非常廣泛,高光譜遙感圖像主要以降低光譜維度和提取光譜維度特征為主。
? 上一節(jié)的特征選擇就講到了在原始特征空間進行特征選擇形成原始空間的一個子空間的特征選擇方法,接下來介紹線性變換方法 :$Y=BX$ ,從高維數(shù)據(jù)空間中,產(chǎn)生一個合適的低維子空間(不是簡單的特征選擇組合),使數(shù)據(jù)在這個空間的分布可以在某種最優(yōu)意義上描述原來的數(shù)據(jù)。
3.2.1 主成分分析
主成分分析(PCA)是最基本的高光譜數(shù)據(jù)降維方法,在高光譜數(shù)據(jù)壓縮、去相關(guān)、消噪和特征提取中發(fā)揮了巨大的作用。PCA 變換又稱為霍特林變換(hotelling transform)和K-L (karhunen-loeve)變換。變換后的各主成分分量彼此不相關(guān),且隨主成分編號的增加該分量包含的信息量減少。
在高光譜遙感數(shù)據(jù)的PCA變換中,一般將每個波段當(dāng)作一個向量來處理,設(shè)高光譜遙感數(shù)據(jù)有$p$個波段,圖像空間維度為$m \times n$,則具體處理流程:
- 圖像向量化:輸入圖像數(shù)據(jù)可以表示成$\bf{X = (x_1,x_2,\cdots, x_p)^T}$,其中 $x_i$ 表示為一個 $N \times 1$ 列向量,這里有$N=m \times n$。即將圖像按行或按列展開有規(guī)則連接起來,稱為一個向量。
- 向量中心化:將向量組中的所有向量減去向量組的均值向量,即 $\bf{Y =X-E(X)}$。
- 計算向量組 $\bf{Y}$ 的協(xié)方差矩陣 $\Sigma$。
- 求協(xié)方差矩陣 $\Sigma$的特征值矩陣 $\Lambda$ 和特征向量矩陣 $\bf{A}$。
- 進行主成分變換, $\bf{Z=A^TY}$。
PCA變換是基于信息量的一種正交線性變換,變換后的圖像信息主要集中在前幾個主成分分量中,在變換域中丟棄信息量小的成分分量,經(jīng)過反變換后仍能得到復(fù)原圖像的近似圖像。
在PCA變換的基礎(chǔ)上提出了分塊主成分分析方法、定向主成分分析方法(DPCA)和選擇主成分方法(selective PCA)。
但PCA 變換存在兩個明顯的缺陷:一是圖像數(shù)值變換影響明顯;二是變換后的信噪比并不一定隨著主成分編號的增加而降低。針對這兩個問題分別發(fā)展了標(biāo)準(zhǔn)化的PCA(standardized PCA, SPCA) 和殘差調(diào)整的PCA(residual-scaled PCA, RPCA)。
3.2.2 最大噪聲分?jǐn)?shù)變換
? 當(dāng)噪聲方差或噪聲在圖像各波段分布不均勻時,基于方差最大化的PCA方法并不能保證圖像質(zhì)量隨著主成分的增大而降低。所以這里引入最大噪聲分?jǐn)?shù)(maximum noise fraction,MNF) 變換 ,該變換根據(jù)圖像質(zhì)量排列成分。MNF 方法主要采用SNR和噪聲比例來描述圖像質(zhì)量參數(shù)。
假設(shè)$\bf{X = [x_1,x_2,\cdots, x_p]^T}$是 $p \times N$ 矩陣,行向量組的均值向量 $E(X) = 0$,協(xié)方差矩陣 $D(X) = \Sigma$ ,假設(shè)
$$
\bf{X= S+N}
$$
其中$\bf{S}$和$\bf{N}$分別指圖像中的信號和噪聲,且兩者不相關(guān)。
設(shè) $\Sigma_S$ 和 $\Sigma_N$ 分別為$\bf{S}$和$\bf{N}$的協(xié)方差矩陣。這里假設(shè)噪聲為加性噪聲,則噪聲比例可表示為:
$$
\bf{Var{N }/Var{X }}
$$
MNF 變換是一種線性變換,則有
$$
\bf{Z_i= a_i^TX, i =1,\cdots, p}
$$
$\bf{Z_i}$ 的噪聲比例在所有正交于$\bf{Z_j}(j= 1,\cdots,i-1)$ 的成分中最大,將 $a_i$標(biāo)準(zhǔn)化,
$$
\bf{a_i^T\Sigma a_i = 1}
$$
由此,MNF變換表示為:
$$
\bf{Z= A^TX}
$$
式中,線性變換系數(shù)矩陣 $\bf{A=[a_1,a_2,\cdots, a_p]}$為矩陣 $\bf{\Sigma^{-1} \Sigma_N}$的特征向量矩陣,則有
$$
\bf{\Sigma^{-1} \Sigma_N}A = \Lambda A
$$
式中,對角線矩陣 $\Lambda$ 為特征值矩陣,第$i$個元素為特征值 $\lambda_i$,對應(yīng)成分的噪聲比例為
$$
\bf{ \frac {Var{a_i^TN }} {Var{a_i^TZ }} = \frac {a_i^T\Sigma_N a_i} {a_i^T\Sigma a_i} }
$$
MNF 變換最后變換結(jié)果的成分按照信噪比的大小排序。
3.2.3 其他常見變換
其他常見的變換包含 最小/最大自相關(guān)因子分析(minimum/maximum autocorrelation factor, MAF)、 噪聲調(diào)整的主成分分析(NPCA) 、 典型相關(guān)分析(CCA)、 獨立成分分析(independent compnent analysis, ICA)、 投影尋蹤(projection pursuit, PP) 、 非負(fù)矩陣分解 和 非線性主成分分析(Kernel PCA, KPCA)等。
這些方法都各有其局限性和適用范圍,需要根據(jù)數(shù)據(jù)質(zhì)量和不同的應(yīng)用需要選擇適宜的方法。
通過對常用的 CPCA、SPCA、MAF 和MNF 的優(yōu)缺點進行總結(jié),比較在目標(biāo)探測的高光譜數(shù)據(jù)降維中的方法,得到下表性能分析:

可以由表總結(jié)為:
- CPCA 的優(yōu)勢在于信息損失小,變換后數(shù)據(jù)結(jié)構(gòu)變化小,但是該方法受數(shù)值和噪聲影響大;
- SPCA的優(yōu)勢在于受數(shù)值影響小,且在信息保留和數(shù)據(jù)結(jié)構(gòu)保留保持兩方面也不錯,但該方法受噪聲影響大;
- MNF 受數(shù)值和噪聲影響小,同時信息損失小,但變換后數(shù)據(jù)結(jié)構(gòu)影響很大;
- MAF 性能最差,不適用于目標(biāo)探測中的高光譜數(shù)據(jù)降維
4.高光譜圖像混合像元
? 遙感器所獲取的地面反射或發(fā)射光譜信號是以 像元(pixel) 為單位記錄的。由于高光譜成像光譜儀在獲取大量波段時,會導(dǎo)致其每個波段的輻射信號較弱,為了提高信噪比、保證圖像質(zhì)量,就需要保證一定角度的瞬時視場角(IFOV),因此,相比全色和多光譜圖像,高光譜圖像的空間分辨率低,使得混合像元的問題尤為突出。
? 所以高光譜圖像無法利用傳統(tǒng)的圖像空間信息進行分析的方法,而是利用其上百個波段豐富的光譜信息,從光譜維來挖掘圖像的信息。
4.1 非線性光譜混合模型和線性光譜混合模型
? 物體的混合和物理分布的空間尺度決定了非線性的程度,大尺度的光譜混合完全可以被看作是一種線性混合,二小尺度的內(nèi)部無核混合是非線性的。在高光譜應(yīng)用中,利用非線性模型計算出的結(jié)果比線性模型計算出的結(jié)果要好,但是其需要輸入眾多的參數(shù),這個實際的應(yīng)用帶來了困難。
非線性模型
- Hapke 混合光譜模型
- K-M(KUBELK-MUNK) 混合光譜理論模型
- 基于輻射通道密度理論的植被、土壤光譜混合模型
- SAIL 模型
- PROSPECT 模型和PROSAIL 模型
線性模型(LSMM)
當(dāng)入射光在地物之間不存在多次散射時,在一定IFOV內(nèi)所形成的混合像元可以通過線性混合模型(LSMM)進行描述。
4.2 光譜解混
? 解決混合像元問題的過程稱為混合像元分解或光譜解混,就是根據(jù)遙感圖像提供的信息判斷每個混合像元是由哪些純像元以怎樣的方式混合的。但是,嚴(yán)格意義上的純像元實際是不存在的,所以在進行解混時,通常是用圖像中包含某種比例很高特征地物的像元代替純像元。這些代替純像元的近似純像元,被稱為端元。
線性光譜解混是利用LSMM 將遙感圖像$\bf{X}$ 中每個混合像元分解成其端元和對應(yīng)豐度,從而得到端元矩陣 $\bf{E}$ 和 豐度矩陣(即所占比例) $\bf{A}$ 的過程。即
$$
\bf{X_{L \times n} = E_{L \times m} A_{m \times n} + \epsilon _{L \times n}}
$$
基本工作分兩步:端元提取,即確定$\bf{E}$,豐度反演,即確定 $\bf{A}$。
- 確定端元數(shù)目,在少數(shù)波段的多光譜圖像中可使用PCA 根據(jù)協(xié)方差特征值的大小確定;在高光譜中使用Neyman-Pearson 探測理論的特征閾值分析分析方法確定,(確定數(shù)目中還需要對噪聲進行評估,可采用光譜維去相關(guān)(SSDC)法);
- 端元提取:MaxV 方法直接用于端元提取,N-FINDER 方法需先降維再提取端元,采用降維時,提取效果:$MaxV>MNF>MAF>CPCA>SPCA$ ;
- 端元光譜變異性:由于非線性因素的影響,端元的光譜存在變異性,即同一類型存在多種端元,這也是線性光譜解混誤差的主要因素之一。混合像元以及端元的光譜變異性,都是對客觀事物的不確定性描述,可用模糊子集和模糊測度的思想來解決;
常用的端元提取方法還有:
- 純像元指數(shù)(pure pixel index, PPI) 算法;
- 改進的快速迭代PPI(faster iterative PPI, FIPPI) 算法;
- 內(nèi)部最大體積(N-FINDER)算法;
- 頂點成分分析(vertex component analysis,VCA) 算法;
- 基于最大距離(maximum distance, MaxD) 算法;
- 基于最大體積(maximum volume, MaxV)算法;
- 定量化獨立成分(ICA)及其衍生算法等。
當(dāng)?shù)玫?strong>端元矩陣 $\bf{E}$ 后,就要通過豐度反演求解高光譜圖像中每個像元里各個端元所占比例,即求 豐度矩陣$\bf{A}$ 的過程。
常用的方法有:
- 最小二乘法(LS):
- 無約束(UCLS)
- "和為1"約束(SCLS)
- “非負(fù)”約束(NCLS)
- 全約束(FCLS)
- 濾波向量(FV)法
- 迭代光譜混合分析(ISMA)法等
5.高光譜遙感數(shù)據(jù)監(jiān)督分類
高光譜圖像數(shù)據(jù)將地物光譜信息和圖像信息融為一體,其數(shù)據(jù)具有幾何空間、光譜特征空間兩類表達方式。
幾何空間:直觀表達每個像元在圖像中的空間位置以及它周邊像元之間的相互關(guān)系,為高光譜圖像處理提供空間信息。
光譜特征空間: 高光譜遙感圖像每個像元對應(yīng)著多個成像波段的反射值。近似連續(xù)的光譜曲線表示為一個$N$維向量,向量在不同波段值的變化反映了其代表的目標(biāo)的輻射光譜信息,其優(yōu)勢是特征維度的變化和擴展性。我們處理將高光譜像元作為高維特征空間的數(shù)據(jù)點,根據(jù)數(shù)據(jù)的統(tǒng)計特性來建立分類模型,但是它的弱點是無法表達像元間的幾何位置關(guān)系。
監(jiān)督分類常用于高光譜圖像數(shù)據(jù)的定量分析,其主要流程是:首先,利用分類器對已知類別機器對應(yīng)的訓(xùn)練樣本進行學(xué)習(xí),獲取各圖像上各類別像元的分類特征;然后,選擇適當(dāng)?shù)姆诸惻袚?jù),根據(jù)分類的決策準(zhǔn)則進行分類。
一般按以下步驟進行:
- 高光譜數(shù)據(jù)選擇。
- 圖像的預(yù)處理。即幾何配準(zhǔn)、校正等,確保獲取正確光譜和幾何信息。
- 確定地物種類。即根據(jù)提取的訓(xùn)練數(shù)據(jù)特征確定分類類別。
- 選擇訓(xùn)練樣本。
- 特征提取和特征選擇。選擇各類地物可區(qū)分性最強的特征從而提高分類精度。
- 選擇合適的分類方法進行分類。
- 分類后處理。傳統(tǒng)基于像元分類方法分類后可能存在大量噪聲及孤立像元,根據(jù)地物的連續(xù)性,利用主成分濾波等方法減少該因素影響,從蹄提高分類精度。
- 分類結(jié)果評價。根據(jù)已知類別的測試數(shù)據(jù)類別與分類結(jié)果比較,確認(rèn)分類的精度與可靠性。
5.1 基于光譜特征空間分類
? 基于光譜特征空間的高光譜圖像分類方法主要是建立在對高光譜圖像光譜特征提取和變換的基礎(chǔ)上,分為兩種思路:一種是基于地物物理光學(xué)性質(zhì)的光譜曲線來進行地物識別,代表性方法是光譜特征匹配方法;另一種是基于特征空間的分類方法,主要利用數(shù)據(jù)的統(tǒng)計特征來建立分類模型,主要方法有傳統(tǒng)的遙感分類方法以及神經(jīng)網(wǎng)絡(luò),支持向量機等復(fù)雜的圖像分類方法。
5.1.1 光譜特征匹配分類方法
基于光譜曲線進行分類識別是利用光譜庫中已知的光譜數(shù)據(jù),采用匹配的算法來識別圖像中地面覆蓋類型。這種匹配既可以是全譜段范圍內(nèi)比較,也可以是感興趣波段的光譜比較。
基于光譜間最小距離的匹配算法是在計算未知光譜與參考光譜距離后,再根據(jù)最最小二乘原則進行匹配的分類方法。該方法對噪聲敏感,所以匹配前需要去噪預(yù)處理。
光譜角度填圖(spectral angle mapping, SAM)方法 把光譜看作是光譜空間的多維矢量,計算兩光譜向量的廣義夾角,夾角越小,光譜越相似,最終根據(jù)相似性閾值對未知像元光譜進行分類。SAM 方法的顯著特征是夾角值與光譜向量模無關(guān),只比較光譜在形狀上的相似性,這也是SAM方法與前者的區(qū)別與優(yōu)勢。
高光譜圖像的光譜波段間隱含這特定的物理含義,光譜曲線的形狀特征是地物內(nèi)在物理化學(xué)性質(zhì)的外在反映。
5.1.2 遙感圖像統(tǒng)計模型分類方法
基于統(tǒng)計的極大似然分類是傳統(tǒng)遙感圖像分類中應(yīng)用最廣泛的分類方法,在極大似然分類器中,首先為簡化分類過程,假設(shè)高光譜圖像每類地物的概率密度都服從多維正態(tài)分布,然后利用分類訓(xùn)練樣本分別對統(tǒng)計參數(shù)進行估計獲得其概率密度函數(shù),最后利用Bayes 公式將最大似然概率公式變?yōu)?br>
$$
p(x|w_i)p(w_i) \geq p(x|w_j)p(w_j)
$$
式中, $p(w_i)$和 $p(w_j)$ 分別是類$i$與類$j$的先驗概率分布,實際中由于無法估計,假設(shè)其相等。所以在實際分類過程中,將各像元劃分到其屬于圖像上不同類別的概率中較大的那一類中去。
不足:要想獲得好的效果,統(tǒng)計參數(shù)的估計變得十分重要;為了獲得可靠的參數(shù),每個類別必須有足夠的訓(xùn)練樣本,這對于上百個波段的高光譜圖像是很困難的。
5.1.3 高光譜圖像神經(jīng)網(wǎng)絡(luò)的方法
后面結(jié)合深度學(xué)習(xí)最新知識再詳細介紹。
不足:高光譜圖像分類時,經(jīng)常遇到“同物異譜”想象,這使得神經(jīng)網(wǎng)絡(luò)的分類算法難于收斂,嚴(yán)重降低分類精度。
5.1.4 高光譜圖像支持向量機的方法
支持向量機方法用于高光譜圖像分類的優(yōu)點是能夠直接對高維數(shù)據(jù)處理,不必經(jīng)過降維處理,而采用全部波段進行分類,保證了光譜信息的充分性。
原始SVM 算法是二分類器,在高光譜圖像的多分類以及精細分類中,采用多個SVM 組合或級聯(lián)的方式實現(xiàn)多分類。
5.2 幾何空間與光譜特征空間結(jié)合的高光譜圖像分類
基于光譜特征空間的高光譜圖像分類方法是將高光譜數(shù)據(jù)作為一種無序的待聚類數(shù)據(jù)集合,沒考慮像元點的幾何空間特征,綜合高光譜圖像的幾何空間特征和光譜特征空間進行分類,能夠有效提高分類精度。
5.2.1 基于同質(zhì)地物提取的高光譜圖像分類方法(ECHO)
前提:圖像空間分辨率較高(優(yōu)于5m),常用實驗數(shù)據(jù)集如AVIRIS Data 大約20m左右
主要思想:首先將圖像劃分為不同的圖像對象,圖像對象為形狀與光譜特征具有相似性的同質(zhì)區(qū)域;對于沒有劃入同質(zhì)區(qū)域的像元利用極大似然分類器對它們進行分類最終獲取分類結(jié)果。
5.2.2 紋理信息輔助下的高光譜圖像分類
利用灰度共生矩陣進行紋理統(tǒng)計。
5.3 面向?qū)ο蟮母吖庾V遙感圖像分類
? 面向?qū)ο蠓诸惖奶攸c即分類的最基本對象從像元轉(zhuǎn)換到圖像對象。分類的核心是高光譜圖像的分割,在這個階段應(yīng)該結(jié)合光譜信息和空間信息。

上圖是面向?qū)ο蟮母吖庾V圖像分類框架。
5.4 高光譜圖像的分類精度評價
5.4.1 誤差矩陣
誤差矩陣的主體是一個 $k \times k$ 的方陣,其中列為地面參考驗證信息,行為分類結(jié)果,矩陣的對角元表示被分到正確類別的像元個數(shù),對角線以外的元素表示錯分的誤差。
其中,生產(chǎn)者精度(PA)
$$
PA_i = \frac{x_{i,i}}{x_{+i}}
$$
用戶精度(UA)
$$
UA_i = \frac{x_{i,i}}{x_{i+}}
$$
5.4.2 漏分誤差和多分誤差
漏分誤差(OE)是指類別$i$在誤差矩陣中,有多少被錯誤分到了其他類別,類別$i$的漏分誤差
$$
OE_i =1- \frac{x_{i,i}}{x_{+i}}
$$
多分誤差(CE)是將其他類別像元錯誤劃分到$i$類中,某類別$i$的多分誤差為
$$
CE_i =1- \frac{x_{i,i}}{x_{i+}}
$$
5.4.3 Kappa 分析
Kappa 分析是一種定量評價遙感分類圖與參考數(shù)據(jù)之間一致性或精度的方法,能識別整體圖像的分類誤差性。
$$
Kappa = \frac{總體精度-期望精度}{1-期望精度}
$$
計算得到
$$
Kappa = \frac {N \sum_{i=1}^kx_{i,i} - \sum_{i=1}^k(x_{i+} \times x_{+i})} {N^2 - \sum_{i=1}^k(x_{i+} \times x_{+i}) }
$$
6.高光譜圖像非監(jiān)督分類
高光譜圖像的非監(jiān)督分類算法還是采用傳統(tǒng)遙感中的非監(jiān)督方法,如 K-means 算法、ISODATA 算法、FCM 算法等算法以及它們的優(yōu)化算法。
高光譜圖像的非監(jiān)督分類使用過程中需要注意這幾個問題:
- 高光譜圖像的波段眾多,在自學(xué)習(xí)中會產(chǎn)生大量冗余,分類前進行特征提取和選擇有利于提高自學(xué)習(xí)過程效率;
- 可以充分利用高光譜圖像中端元提取、光譜分析等手段獲得較精確的類別初值,輔助非監(jiān)督分類;
- 選擇非相似性度量時,需要充分考慮地物光譜特征,適當(dāng)選擇;
- 利用搜索算法求解非監(jiān)督分類目標(biāo)函數(shù)時,嘗試?yán)萌炙阉魉惴ù婢植克阉魉惴ㄌ岣叻潜O(jiān)督分類精度。
