認識Task Flow
TaskFlow是一個python庫,用來簡化任務的執行管理,同時,實現任務的一致性、可擴展和可靠性。TaskFlow支持創建不同的 task,并以聲明的方式集成到一個 flow 中,這些 flow 會通過 engine 執行、停止、繼續和恢復。
優點
- 彈性的增加狀態
- 自然聲明構造
- 簡單可測試(每個 task 只做一件事)
- 工作流可插拔
- 容錯性
- 簡單的故障恢復
概念示例
偽代碼展示了 flow 類似于SQL事務的執行模式
START TRANSACTION task1: call nova API to launch a server || ROLLBACK task2: when task1 finished, call cinder API to attach block storage to the server || ROLLBACK ...perform other tasks... COMMIT
why
OpenStack 的代碼正在有組織的增長,但是如果進程被意外中斷,卻沒有一個可以安全恢復或回滾代碼的標準;大多數項目并沒有使 task 可以重啟或恢復,簡單的挑高或恢復的場景在今天的代碼里已幾乎不可能。通過Taskflow的推廣,甚至在沒有HA的情況下,使OpenStack變的可信和可靠。
一些使用場景
服務停止、更新、重啟
目前Openstack的大部分服務都沒有對服務的強制停止做任何處理,使任務處于不可調和的狀態。比如,一個任務在運行過程中被終止,可能會變為不可恢復的狀態,或成為遺留資源。TaskFlow可以跟蹤任務的關聯狀態,當服務重啟后,可以很容易的恢復或者回滾。Orphaned resources(僵尸資源)
由于現在OpenStack的項目缺乏事務語義,所以會留下一些資源成為孤兒狀態,或ERROR的狀態,在自動化系統(Heat)情況下,這種狀況是非常不能令人接收的,因為非常難分析哪些是要被清除的孤兒資源。
Taskflow提供其以任務為導向的模型將能正確地追蹤資源的變動,這就容許在一些資源上的動作可以自動地被撤銷,以確定沒有資源被稱為“僵尸”。Metrics and history(度量和歷史)
當OpenStack服務被組織進 task 和 flow 的對象和模式時,通過將記錄 task 在運行時的度量/歷史,這些服務便自動獲得了簡單的增加度量報告和歷史操作的能力。進度/狀態跟蹤
Openstack中,有很多場景需要記錄和跟蹤任務的進度,TaskFlow提供了一種內建的通知機制實現任務進度的跟蹤。
設計
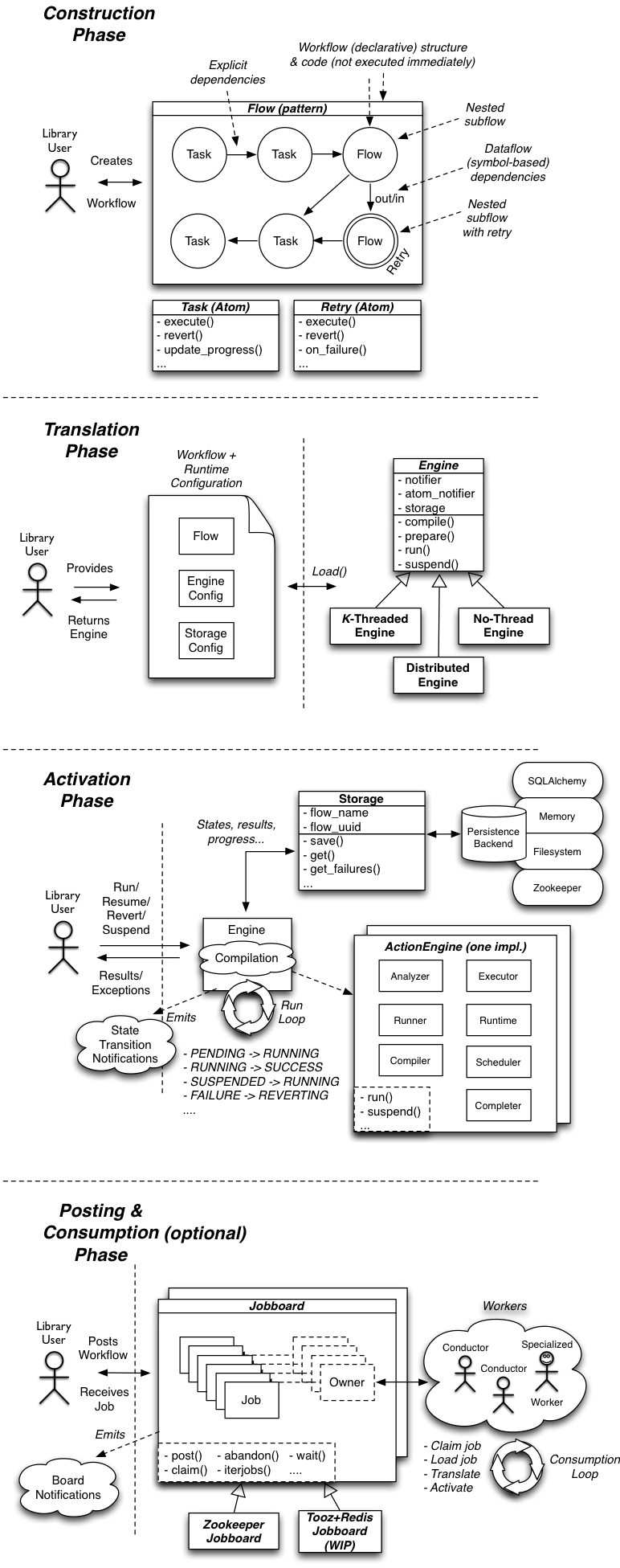
構成
- Atoms
TaskFlow的最小單元,是其他類型的基礎。atom是一種命名對象,通過操作輸入數據實現流程中的一個動作,或者輸出一個處理結果。我理解atom是一個抽象概念,其中定義了任務、操作和數據。 - Task
task派生于一個atom,包括一個 execute & rollback序列每個task都繼承自Task,其中定義了一系列的屬性和方法。
- Retry
retry也是派生于一個atom,是一個特殊的單元,實現對錯誤的處理,控制flow的異常情況,必要時,能夠以其他參數重試另一個atom。retry基類的派生類必須提供on_failure()方法,實現對異常的處理。

參考
TaskFlow官方文檔
An Introduction to OpenStack TaskFlow with Python
