Java構(gòu)建汽車無人駕駛:汽車目標檢測
Java Autonomous Driving: Car Detection
原文地址: https://dzone.com/articles/java-autonomous-driving-car-detection-1
在這篇文章中,我們將用Java構(gòu)建一個實時視頻對象檢測應(yīng)用程序,用于汽車檢測,這是自動駕駛系統(tǒng)的一個關(guān)鍵組件。 在之前的文章中,我們能夠構(gòu)建一個圖像分類器(貓與狗); 現(xiàn)在,現(xiàn)在我們要檢測物體(即汽車,行人),并用邊框(矩形)標記它們。 隨意下載代碼或使用自己的視頻運行應(yīng)用程序(簡短視頻示例)。
目標檢測本質(zhì)
Object Classification(物體分類)
首先,我們遇到了對象分類的問題,比如我們想知道在一個圖片中是否包含一個特定的物體,在下圖中即圖像中是否包含汽車。

我們在前一篇文章中提到了使用現(xiàn)有的架構(gòu)VGG-16和遷移學習去構(gòu)建圖像分類器。
Object Localization(物體定位)
現(xiàn)在我們可以說,我們擁有高置信度去判斷圖片中是否含有某一特定物體,我們就面臨著圖像中物體定位的挑戰(zhàn)。通常,這是通過用矩形或邊界框標記對象來完成的。

除了圖片分類,我們需要額外去識別物體在圖像中的位置。這通過定義邊界框來完成。
邊界框通常表現(xiàn)為物體的中心
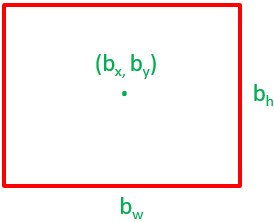
現(xiàn)在,我們就需要為我們的訓(xùn)練集數(shù)據(jù)中為圖像中的每一個物體都定義這四個變量。此外,網(wǎng)絡(luò)不僅會輸出圖像類別編號(即20%cat [1],70%dog [2],10%tiger [3])的概率,還會輸出上面定義邊界框的四個變量值。
提供邊界框點(中心,寬度,高度),我們的模型通過給我們更詳細的圖像內(nèi)容視圖輸出/預(yù)測更多的信息。

不難想象,在圖像訓(xùn)練數(shù)據(jù)中加入更多點可以讓我們更深入地了解圖像。 例如,在人臉上(即嘴巴,眼睛)的點可以告訴我們這個人在微笑,哭泣等等。
Object Detection(目標檢測)
我們可以更進一步的定位圖像中的多個物體。

雖然結(jié)構(gòu)沒有太大變化,但這里的問題變得更加困難,因為我們需要準備更多的數(shù)據(jù)(多邊界框)。 原則上,我們只是將圖像分成較小的矩形,對于每個矩形,我們都有相同的額外的五個變量 -
Sliding Window Solution(滑動窗口解決方案)
這是一個非常直觀的解決方案。這個想法是不使用一般的汽車圖像,而是盡可能的裁剪圖像使得圖像中只含有汽車。
我們使用裁剪之后的圖像,去訓(xùn)練一個網(wǎng)絡(luò)結(jié)構(gòu)類似于VGG-16或者其他深度網(wǎng)絡(luò)的卷積神經(jīng)網(wǎng)絡(luò)。


這種方法的結(jié)果很好,但是這種模型只能用于檢測圖像中是否含有汽車,所以在檢測真實場景的圖像中會有問題,因為它里面包含有其他的物體(比如說樹、人、交通標志等)。
除此之外,現(xiàn)實圖像一般也比訓(xùn)練數(shù)據(jù)的尺寸要大。

為了克服這些問題,我們可以只分析圖像中的一部分并且分析這一部分是否含有汽車的一部分。更精確的說法是,我們使用滑動的矩形框掃描整個圖片,在每一次掃描的時候使用我們的模型來判斷這一部分是否含有汽車。讓我們看一個示例:

總之,我們使用正常的卷積神經(jīng)網(wǎng)絡(luò)(VGG-16)來訓(xùn)練帶有不同大小裁剪圖像的模型,然后使用矩形掃描物體(汽車)的圖像。 我們可以看到,通過使用不同大小的矩形,我們可以計算出不同的車輛形狀和位置。
這個算法并不復(fù)雜,并且奏效。但是這個算法擁有兩個缺點。
-
第一個問題是性能問題。我們必須調(diào)用模型預(yù)測結(jié)果很多次。每一次矩形框移動,我們都需要調(diào)用模型用于獲取預(yù)測結(jié)果 - 并且我們需要使用不同的矩形框大小來重復(fù)做這一件事情。其中一個解決性能問題的方法是增加矩形框的步長(使用大步長),但是這樣我們可能會檢測不出來某些物體。在過去,模型主要是線性的,并且具有手動設(shè)計的特征,因此預(yù)測并不昂貴。 所以這個算法用來做得很好。 目前,網(wǎng)絡(luò)規(guī)模(VGG-16的參數(shù)為1.38億),這種算法速度很慢,對于像自主駕駛這樣的實時視頻對象檢測幾乎沒有用處。
 此處輸入圖片的描述
此處輸入圖片的描述
另外一個導(dǎo)致算法性能不佳的原因是:當我們移動矩形框時(向右和向下移動),許多共用的像素點并沒有重用而是重復(fù)計算了。在下一部分,我們將使用最新的卷積來克服這個問題。
 此處輸入圖片的描述
此處輸入圖片的描述 即使使用不同大小的矩形框來掃描圖像,我們依舊可能無法檢測出圖像中包含的物體。模型可能無法輸出準確的邊界框信息;例如:這個矩形中只包含物體的一部分。在下一個部分中我們將探討 YOLO (you only look once) 算法,這個將會為我們解決這個問題。
Convolutional Sliding Window Solution(卷積滑動窗口解決方案)
我們看到滑動窗口因為無法重用大量已經(jīng)計算過后的數(shù)值有性能問題。每一次滑動窗口移動之后,我們都需要計算模型中大量的參數(shù)(可能上百萬的參數(shù)),為了獲取一個預(yù)測值。在現(xiàn)實中,我們可以引入卷積結(jié)構(gòu)來重用這些計算結(jié)果。
Turn Fully Connected Layers Into Convolution(從全連接網(wǎng)絡(luò)轉(zhuǎn)向卷積神經(jīng)網(wǎng)絡(luò))
我們在前一篇文章的最后看到,圖像分類結(jié)構(gòu) - 無論其大小和配置如何 - 訓(xùn)練不同層數(shù)的全連接層網(wǎng)絡(luò),輸出的數(shù)量取決于分類物體的種類。
為了簡單起見,我們將以較小的網(wǎng)絡(luò)模型為例,但對于任何卷積網(wǎng)絡(luò)來說,相同的邏輯都是有效的。(VGG-16,AlexNet)
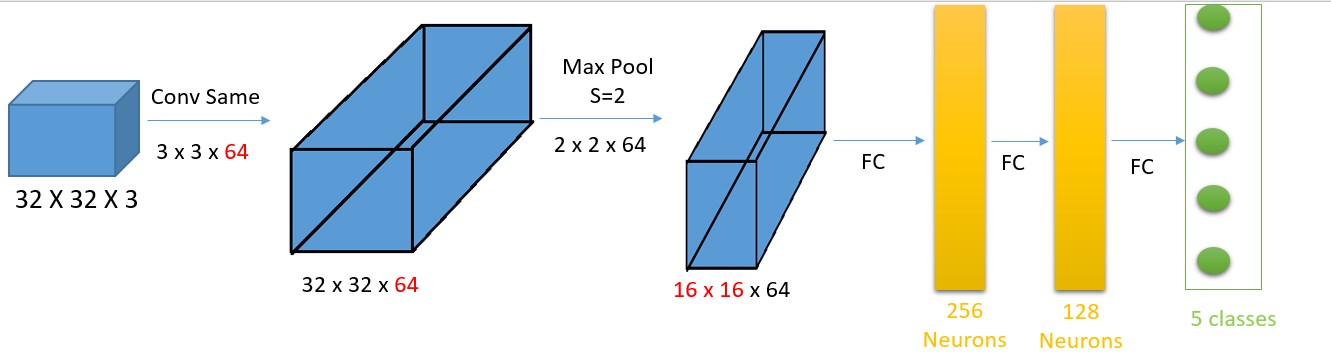
有關(guān)卷積更加直觀詳細的解釋請查看之前一篇文章。
這個簡單的網(wǎng)絡(luò)使用大小為
32 x 32 x 3的彩色圖片作為網(wǎng)絡(luò)的輸入,使用SAME3x3x64 的卷積(這種卷積方式不會改變圖像的寬和高)獲取了一個大小為32 x 32 x 64的輸出(提示,輸出數(shù)據(jù)的第三個維度和卷積和的維度64大小相等,這通常用于對輸入數(shù)據(jù)的增益)。接下來使用最大池化削減寬度和高度,并且保持第三個維度的數(shù)據(jù)不發(fā)生變化(16 x 16 x 64)。在此之后,我們使用神經(jīng)元個數(shù)為256和128的兩層全連接網(wǎng)絡(luò)。在最后我們輸出五個種類的概率(通常使用soft-max)。讓我們看看如何用卷積層替換全連接層,同時保持數(shù)學效果相同(輸入16 X 16 X 64的線性函數(shù))。
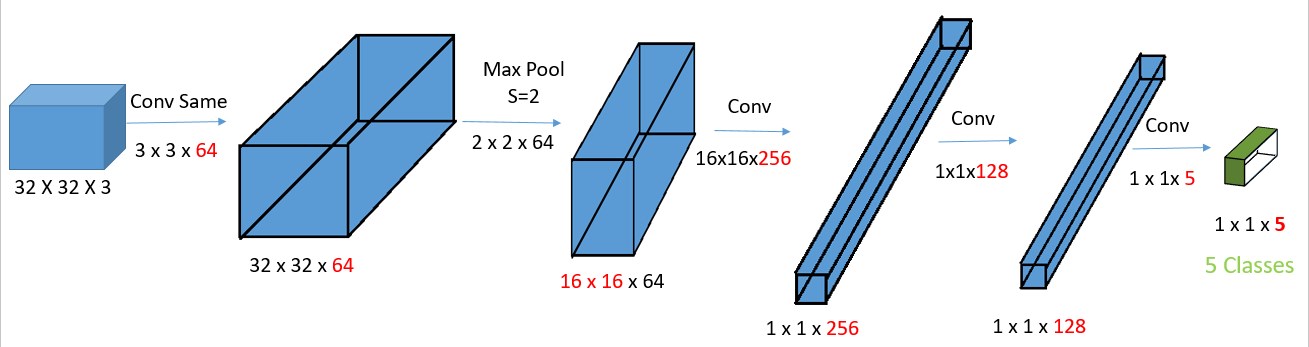
我們只是使用卷積核來代替全連接層。在現(xiàn)實中,
16x16x256的卷積核實際上是一個16x16x64x256的矩陣(多個卷積核),因為卷積核的第三個維度和輸入的第三個維度總是一樣的。為了簡便,我們將其認為是16 x 16 x 256。這意味著,這相當于一個全連接層,因為輸出1 X 1 X 256的每個元素都是輸入16 X 16 X 64的每個元素的線性函數(shù)。
我們?yōu)槭裁匆獙⑷B接(FC)層轉(zhuǎn)換為卷積層的原因是因為這會給我們在選擇輸出方式時帶來更大的靈活性。 借助FC,您將始終具有相同的輸出大小,即類數(shù)。
Convolution Sliding Window(卷積滑動窗口)
想要看到使用卷積網(wǎng)絡(luò)替代全連接層背后的思想,我們需要輸入圖片的大小大于原來的圖片大小-32x32x3。讓我們使用36x36x3的圖片作為輸入。
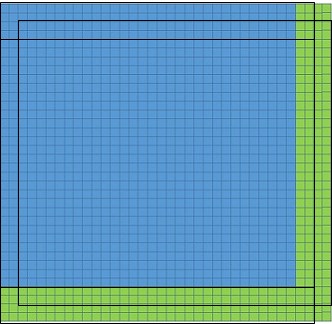
這個圖像 (with green 36 X 36)比原有的圖像(blue 32 X 32)大四行四列。如果我們使用步長為2的滑動窗口和全連接層網(wǎng)絡(luò),我們需要移動原有圖像大小9次才可以覆蓋整個圖像(圖中的黑色矩形示范了其中的三種移動結(jié)果)。與此同時,調(diào)用模型9次。
接下來讓我們嘗試將更大圖像應(yīng)用在我們只使用卷積層的新模型上。
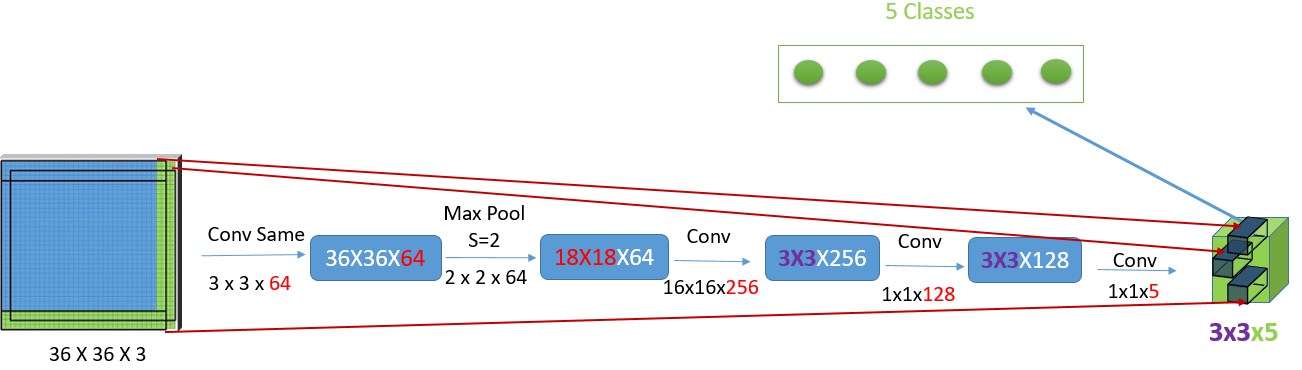
正如同我們所看到的,相比于全連接層的輸出只能為
1x1x5,輸出從1x1x5變成了3x3x5。回想到我們必須移動9次才能覆蓋整個圖片 - 等一下,這是不是正好等于3x3?是的,這些3x3大小的單元表示了每一個滑動窗口的1x1x5的分類概率輸出結(jié)果。這是一種非常先進的技術(shù),因為我們只需一次就可以立即獲得全部九個結(jié)果,而無需多次執(zhí)行帶有數(shù)百萬參數(shù)的模型。
YOLO (You Only Look Once)
雖然我們通過引入卷積滑動窗口的方式解決了性能問題。但是我們的模型依舊不能輸出非常準確的邊界框,即便使用大量不同大小的邊界框。讓我們看YOLO是如何解決這個問題。
首先,我們通常在每一個圖片中標注我們想要檢測的物體。每一個物體都會使用四個變量,通過邊界框的方式進行標注 - 記住這四個變量是物體的中心 ,矩形的高
,矩形的寬
。每個圖像都被會分割成更小的矩形 - 通常分為
19x19個矩形,為了簡單起見,這里分割為8x9。
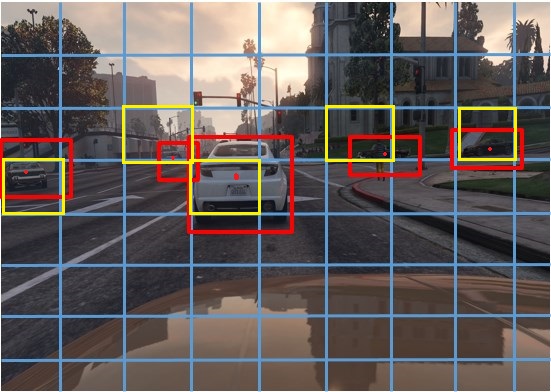
紅色的邊界框和物體都是由很多藍色邊界框的一部分組成的,所以我恩枝江對象和邊界框分配給擁有對象中心的黃色框。我們使用額外的四個變量(除了告知物體為汽車,還額外提供物體的中心,寬度和高度)訓(xùn)練我們的模型,并且將這些變量分配給擁有中心點的邊界框。在神經(jīng)網(wǎng)絡(luò)使用這種標注好的數(shù)據(jù)集訓(xùn)練完成以后,我們將用該模型用于預(yù)測這四個變量的值(除了識別物體的類別),值或者邊界框。
我們不是使用預(yù)定義的邊界框大小進行掃描,而是試圖擬合對象,我們讓模型學習如何用邊界框標記對象; 因此,邊界框現(xiàn)在是靈活的(被學習)。 這樣,邊界框的精度就高得多并且靈活多了。
讓我們來看看現(xiàn)在我們?nèi)绾伪硎据敵觯讼?-車,2-行人這樣的類之外,我們還有額外的四個變量
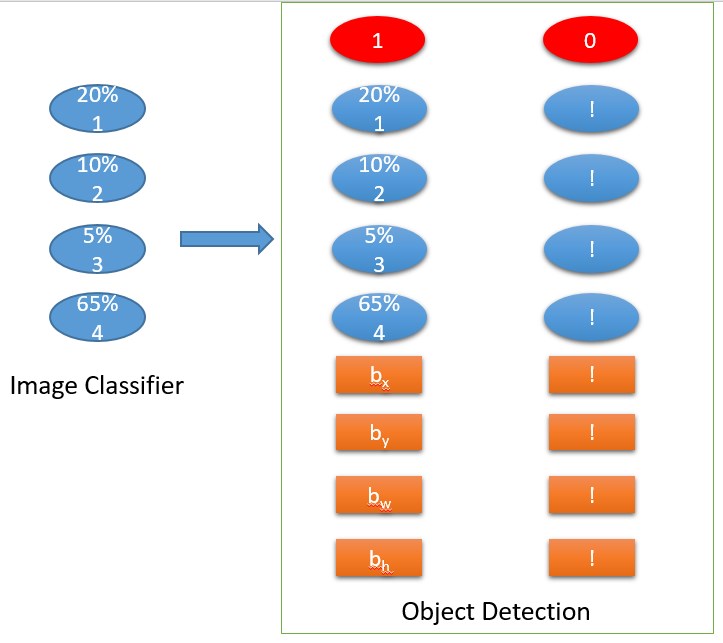
-
(紅色標注) 意味著這里至少有一個我們想要被檢測出來的對象,所以就值得去查看被識別物體的分類概率和邊界框的值。
-
(紅色標注)意味著里面檢測出任何我們想要檢測出來的對象,我們不需要關(guān)心模型預(yù)測出來的分類概率和邊界框的值。
Bounding Box Specification(邊界框識別)
我們需要使用特殊的方法來標記我們的數(shù)據(jù)以便于YOLO算法能正確的運轉(zhuǎn)。YOLO V2格式需要邊界框的維度值為原始圖片寬高的相對值。假設(shè)我們擁有一個300x400大小的圖片,并且邊界框的維度為
。這些值需要轉(zhuǎn)換為
。
這篇文章將會講述如何借助BBox Label Tool工具花費很小的代價來標注我們的數(shù)據(jù)。這個工具標記的邊界框(給我們的是左上的點和右下的點)與YOLO V2格式有些許的不一樣。但是將其轉(zhuǎn)化成為我們想要的數(shù)據(jù)是非常簡單的事情。
除了YOLO需要訓(xùn)練數(shù)據(jù)的標簽,在內(nèi)部實現(xiàn)中,預(yù)測方式也有所不同。
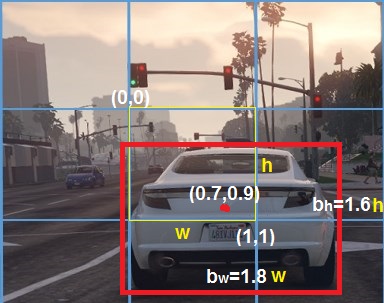
YOLO預(yù)測的邊界框是相對于擁有對象中心的框(黃色)進行定義。黃色框左上角的點定義為(0,0),并且將右下角的點定義為(1,1)。所以中心店
預(yù)測之后,我們可以看到預(yù)測框與開始標記的實際邊界框相交多少。基本上,我們試圖最大化它們之間的交集,所以理想情況下,預(yù)測的邊界框與標記的邊界框完全相交。
在原則上就是這樣!你提供更加專業(yè)的使用邊界框
Two More Problems(還有兩個問題)
即使我們試圖在本篇文章提供更加詳細的解釋,但是在事實中,我們還有兩個小問題需要去解決。

首先,即使在訓(xùn)練時間內(nèi),對象被分配到一個盒子(包含對象中心的盒子),在測試時間(預(yù)測時),幾個盒子(黃色)可能認為它們具有對象的中心(帶有紅色 ),因此為同一個對象定義自己的邊界框。 這是用非最大抑制算法解決的。 目前,Deeplearning4j沒有提供實現(xiàn),所以請在GitHub上找到一個簡單的實現(xiàn)(removeObjectsIntersectingWithMax)。 它的作用是首先選擇最大Pc概率的盒子作為預(yù)測(它不僅具有1或0值,而是可以在0-1范圍內(nèi))。 然后,刪除每個與該框相交超過特定閾值的框。 它再次啟動相同的邏輯,直到?jīng)]有剩下的邊界框。

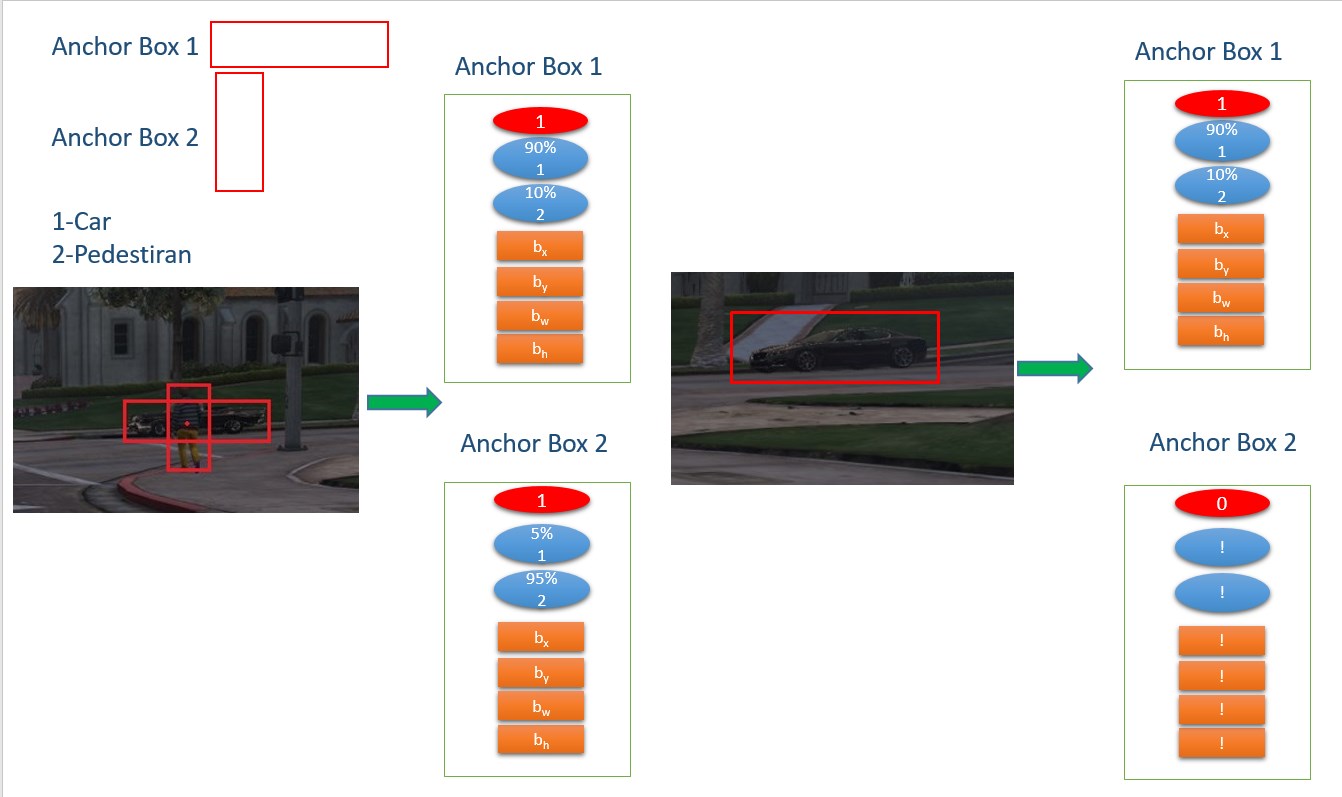
其次,由于我們預(yù)測了多個物體(汽車,行人,交通信號燈等),因此可能發(fā)生兩個或更多物體的中心是一個箱體。 這些情況通過引入錨箱來解決。 使用錨箱,我們選擇幾個邊界框的形狀,我們發(fā)現(xiàn)更多用于我們想要檢測的對象。 YOLO V2文件通過k-means算法實現(xiàn),但也可以手動完成。 之后,我們修改輸出以包含我們之前看到的相同結(jié)構(gòu)(Pc,bx,by,bh,bw,C1,C2 ...),但對于每個選定的錨箱形狀。 所以,我們現(xiàn)在可能有這樣的事情:
Application(應(yīng)用)
訓(xùn)練深度網(wǎng)絡(luò)需要付出很多努力,并需要有意義的數(shù)據(jù)和處理能力。 正如我們在之前的文章中所做的那樣,我們將使用轉(zhuǎn)移學習。 這一次,我們不打算修改架構(gòu)并用不同的數(shù)據(jù)訓(xùn)練,而是直接使用網(wǎng)絡(luò)。
我們打算使用Tiny YOLO; 以下問題引用于網(wǎng)上:
Tiny YOLO基于Darknet參考網(wǎng)絡(luò),速度比普通的YOLO模型快得多,但是相比普通的模型準確率有所降低。 要使用VOC訓(xùn)練的版本:
wget https://pjreddie.com/media/files/tiny-yolo-voc.weights
./darknet detector test cfg/voc.data cfg/tiny-yolo-voc.cfg tiny-yolo-voc.weights data/dog.jpg
好吧,這不是完美的,但兄弟,它確實很快。 在GPU上,它運行速度大于200 FPS。
Deeplearning4j 0.9.1的當前發(fā)行版本不提供TinyYOLO,但0.9.2-SNAPSHOT提供。 所以首先,我們需要告訴Maven在哪里加載SNAPSHOT版本:
<repositories>
<repository>
<id>a</id>
<url>http://repo1.maven.org/maven2/</url>
</repository>
<repository>
<id>snapshots-repo</id>
<url>https://oss.sonatype.org/content/repositories/snapshots</url>
<releases>
<enabled>false</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
<updatePolicy>daily</updatePolicy>
</snapshots>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.deeplearning4j</groupId>
<artifactId>deeplearning4j-core</artifactId>
<version>${deeplearning4j}</version>
</dependency>
<dependency>
<groupId>org.nd4j</groupId>
<artifactId>nd4j-native-platform</artifactId>
<version>${deeplearning4j}</version>
</dependency>
接下來我們要用非常簡短的代碼來加載模型:
private TinyYoloPrediction() {
try {
preTrained = (ComputationGraph) new TinyYOLO().initPretrained();
prepareLabels();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
prepareLabels() 只是使用PASCAL VOC數(shù)據(jù)集中用于訓(xùn)練模型的標簽. 運行 preTrained.summary() 去查看模型架構(gòu)的時候不要感到有任何壓力。
視頻的每一幀是CarVideoDetection使用JavaCV進行捕獲的:
FFmpegFrameGrabber grabber;
grabber = new FFmpegFrameGrabber(f);
grabber.start();
while (!stop) {
videoFrame[0] = grabber.grab();
if (videoFrame[0] == null) {
stop();
break;
}
v[0] = new OpenCVFrameConverter.ToMat().convert(videoFrame[0]);
if (v[0] == null) {
continue;
}
if (winname == null) {
winname = AUTONOMOUS_DRIVING_RAMOK_TECH + ThreadLocalRandom.current().nextInt();
}
if (thread == null) {
thread = new Thread(() -> {
while (videoFrame[0] != null && !stop) {
try {
TinyYoloPrediction.getINSTANCE().markWithBoundingBox(v[0], videoFrame[0].imageWidth, videoFrame[0].imageHeight, true, winname);
} catch (java.lang.Exception e) {
throw new RuntimeException(e);
}
}
});
thread.start();
}
TinyYoloPrediction.getINSTANCE().markWithBoundingBox(v[0], videoFrame[0].imageWidth, videoFrame[0].imageHeight, false, winname);
imshow(winname, v[0]);
因此,代碼正在從視頻獲取幀并傳遞到TinyYOLO預(yù)先訓(xùn)練好的模型。 從那里,圖像幀首先被縮放到416 X 416 X 3(RGB),然后傳給TinyYOLO用于預(yù)測和標記邊界框:
public void markWithBoundingBox(Mat file, int imageWidth, int imageHeight, boolean newBoundingBOx,String winName) throws Exception {
int width = 416;
int height = 416;
int gridWidth = 13;
int gridHeight = 13;
double detectionThreshold = 0.5;
Yolo2OutputLayer outputLayer = (Yolo2OutputLayer) preTrained.getOutputLayer(0);
INDArray indArray = prepareImage(file, width, height);
INDArray results = preTrained.outputSingle(indArray);
predictedObjects = outputLayer.getPredictedObjects(results, detectionThreshold);
System.out.println("results = " + predictedObjects);
markWithBoundingBox(file, gridWidth, gridHeight, imageWidth, imageHeight);
imshow(winName, file);
}
預(yù)測之后,我們應(yīng)該已經(jīng)擁有了邊界框尺寸的預(yù)測值。我們已經(jīng)實現(xiàn)了非最大抑制算法(removeObjectsIntersectingWithMax)因為,正如我們所提到的,YOLO算法在測試時,在預(yù)測每一個對象的時候回擁有不只一個邊界框。相比,我們將會使用
topLeft和bottomRight左上點和右下點。gridWidth和gridHeight使我們打算將圖片分割成為多少個更小的邊界框,在我們的案例中被分割為13x13。w和h為原始圖像的尺寸。
在此之后,除了播放視頻的線程之外我們將會啟用另外一個線程,我們更新視頻以獲取檢測到的對象的矩形和標簽。
考慮我們運行在CPU上時,(實時)預(yù)測的速度非常的快;如果運行在GPU上,我們會獲得更好的實時檢測效果。
Running Application (運行應(yīng)用)
即使你的電腦上沒有安裝Java,這個應(yīng)用可以在沒有任何Java背景知識的條件下下載和運行。你可以嘗試使用自己的視頻。
在源代碼中執(zhí)行RUN類即可運行。如果你不想使用IDE來打開這個工程,你可以運行mvn clean install exec:java命令。
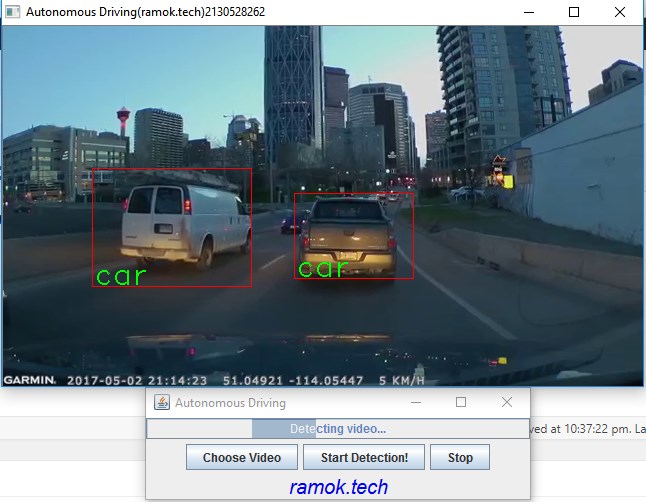
在運行這個應(yīng)用之后,你將會看到如下圖所示的結(jié)果:
Enjoy!
github代碼地址: https://github.com/klevis/AutonomousDriving
gitee開源中國地址: https://gitee.com/sjsdfg/AutonomousDriving
更多文檔可以查看 https://github.com/sjsdfg/deeplearning4j-issues。
你的star是我持續(xù)分享的動力
