引言
之前抓的妹子圖都是直接抓Html就可以的,就是Chrome的瀏覽器F12的
Elements頁面結構和Network抓包返回一樣的結果。后面在抓取一些
網站(比如煎蛋,還有那種小網站的時候)就發現了,Network那里抓包
獲取的數據沒有,而Elements卻有的情況,原因就是:頁面的數據是
通過JavaScript來動態生成的:


抓不到數據怎么破,一開始我還想著自學一波JS基本語法,再去模擬抓包
拿到別人的JS文件,自己再去分析邏輯,然后搗鼓出真正的URL,后來還是
放棄了,畢竟要抓的頁面那么多,每個這樣分析分析到什么時候...

后面意外發現有個自動化測試框架:Selenium 可以幫我們應對這個問題。
簡單說下這個東西有什么用吧,我們可以編寫代碼讓瀏覽器:
- 1.自動加載網頁;
- 2.模擬表單提交(比如模擬登錄),獲取需要的數據;
- 3.頁面截屏;
- 4.判斷網頁某些動作是否發生,等等。
然后這個東西是不支持瀏覽器功能的,你需要和第三方的瀏覽器一起搭配使用,
支持下述瀏覽器,需要把對應的瀏覽器驅動下載到Python的對應路徑下:
Chrome:https://sites.google.com/a/chromium.org/chromedriver/home
FireFox:https://github.com/mozilla/geckodriver/releases
PhantomJS:http://phantomjs.org/
IE:http://selenium-release.storage.googleapis.com/index.html
Edge:https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/
Opera:https://github.com/operasoftware/operachromiumdriver/releases
直接開始本節的內容吧~
1.安裝Selenium
這個就很簡單了,直接通過pip命令行進行安裝:
sudo pip install selenium
PS:想起之前公司小伙伴問過我pip在win上怎么執行不了,又另外下了很多pip,
其實如果你安裝了Python3的話,已經默認帶有pip了,你需要另外配置下環境
變量,pip的路徑在Python安裝目錄的Scripts目錄下~
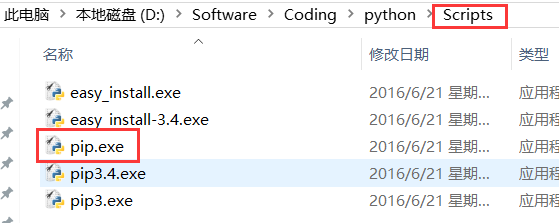
Path后面加上這個路徑就好~

2.下載瀏覽器驅動
因為Selenium是不帶瀏覽器的,所以需要依賴第三方的瀏覽器,要調用第三方
的瀏覽器的話,需要下載瀏覽器的驅動,因為筆者用到是Chrome,這里就以
Chrome為例子吧,其他瀏覽器的自行搜索相關資料了!打開Chrome瀏覽器,鍵入:
chrome://version
可以查看Chrome瀏覽器版本的相關信息,這里主要是關注版本號就行了:
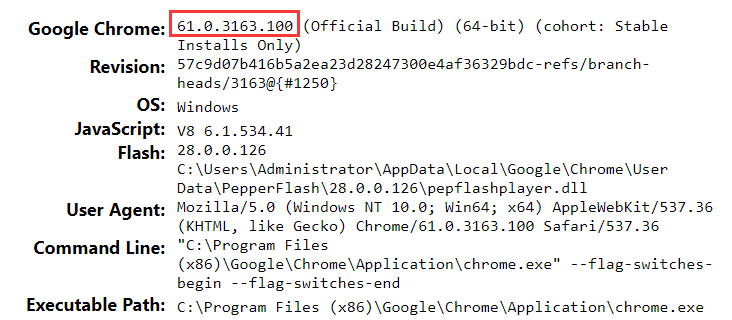
61,好的,接下來到下面的這個網站查看對應的驅動版本號:
https://chromedriver.storage.googleapis.com/2.34/notes.txt

好的,那就下載v2.34版本的瀏覽器驅動吧:
https://chromedriver.storage.googleapis.com/index.html?path=2.34/

下載完成后,把zip文件解壓下,解壓后的chromedriver.exe拷貝到Python
的Scripts目錄下。(這里不用糾結win32,在64位的瀏覽器上也是可以正常使用的!)
PS:Mac的話把解壓后的文件拷貝到usr/local/bin目錄下
Ubuntu的話拷貝到:usr/bin目錄下
接下來我們寫個簡單的代碼來測試下:
from selenium import webdriver
browser = webdriver.Chrome() # 調用本地的Chrome瀏覽器
browser.get('http://www.baidu.com') # 請求頁面,會打開一個瀏覽器窗口
html_text = browser.page_source # 獲得頁面代碼
browser.quit() # 關閉瀏覽器
print(html_text)
執行這段代碼,會自動調起瀏覽器,并且訪問百度:
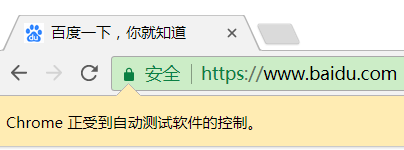
并且控制臺會輸出HTML的代碼,就是直接獲取的Elements頁面結構,
JS執行完后的頁面接下來我們就可以來抓我們的煎蛋妹子圖啦
3.Selenium 簡單實戰:抓取煎蛋妹子圖
直接分析Elements頁面結構,找到想要的關鍵結點:
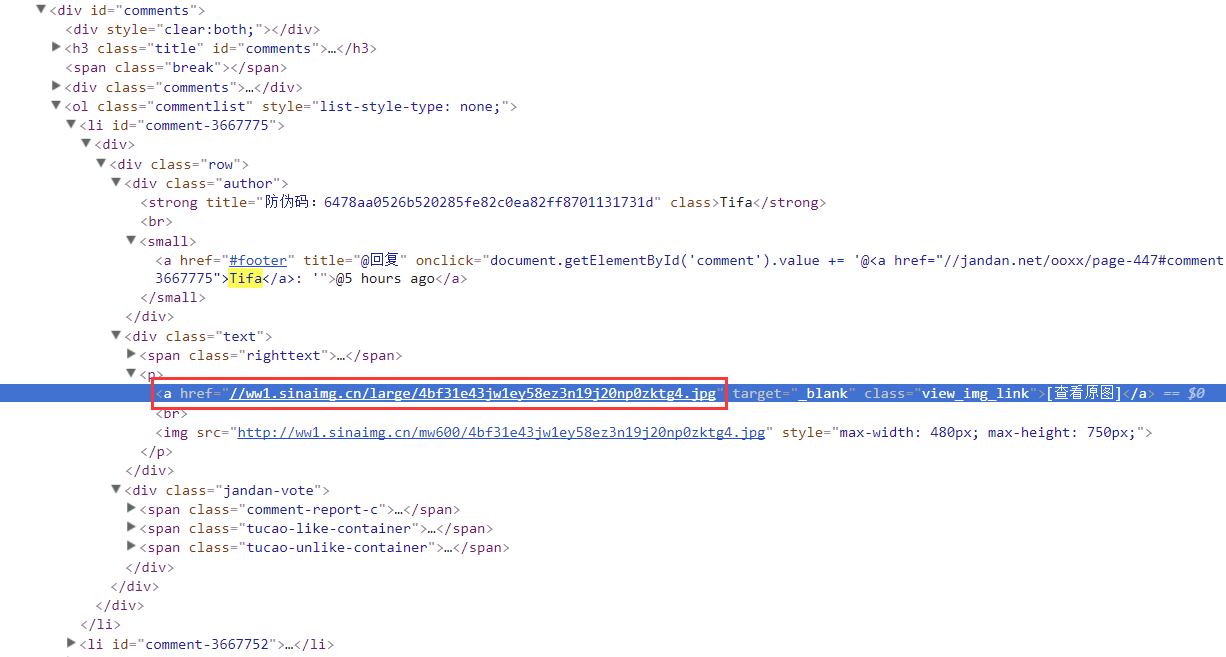
明顯這就是我們抓取的小姐姐圖片,復制下這個URL,看下我們打印出的
頁面結構有沒有這個東西:

可以,很棒,有這個頁面數據,接下來就走一波Beautiful Soup獲取到我們
想要的數據啦~
經過上面的過濾就能夠拿到我們的妹子圖片URL:
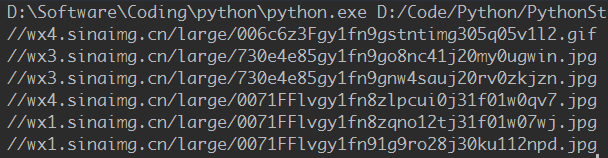
隨手打開一個驗證下,嘖嘖:


看了下一頁只有30個小姐姐,這顯然是滿足不了我們的,我們在第一次加載
的時候先拿到一波頁碼,然后就知道有多少頁了,然后自己再去拼接URL加載
不同的頁面,比如這里總共又448頁:

拼接成這樣的URL即可:http://jandan.net/ooxx/page-448
過濾下拿到頁碼:


接下來就把代碼補齊咯,循環抓取每一頁的小姐姐,然后下載到本地,
完整代碼如下:
import os
from selenium import webdriver
from bs4 import BeautifulSoup
import urllib.request
import ssl
import urllib.error
base_url = 'http://jandan.net/ooxx'
pic_save_path = "output/Picture/JianDan/"
# 下載圖片
def download_pic(url):
correct_url = url
if url.startswith('//'):
correct_url = url[2:]
if not url.startswith('http'):
correct_url = 'http://' + correct_url
print(correct_url)
headers = {
'Host': 'wx2.sinaimg.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.100 Safari/537.36 '
}
try:
req = urllib.request.Request(correct_url, headers=headers)
resp = urllib.request.urlopen(req)
pic = resp.read()
pic_name = correct_url.split("/")[-1]
with open(pic_save_path + pic_name, "wb+") as f:
f.write(pic)
except (OSError, urllib.error.HTTPError, urllib.error.URLError, Exception) as reason:
print(str(reason))
# 打開瀏覽器模擬請求
def browser_get():
browser = webdriver.Chrome()
browser.get('http://jandan.net/ooxx')
html_text = browser.page_source
page_count = get_page_count(html_text)
# 循環拼接URL訪問
for page in range(page_count, 0, -1):
page_url = base_url + '/page-' + str(page)
print('解析:' + page_url)
browser.get(page_url)
html = browser.page_source
get_meizi_url(html)
browser.quit()
# 獲取總頁碼
def get_page_count(html):
soup = BeautifulSoup(html, 'html.parser')
page_count = soup.find('span', attrs={'class': 'current-comment-page'})
return int(page_count.get_text()[1:-1]) - 1
# 獲取每個頁面的小姐姐
def get_meizi_url(html):
soup = BeautifulSoup(html, 'html.parser')
ol = soup.find('ol', attrs={'class': 'commentlist'})
href = ol.findAll('a', attrs={'class': 'view_img_link'})
for a in href:
download_pic(a['href'])
if __name__ == '__main__':
ssl._create_default_https_context = ssl._create_unverified_context
if not os.path.exists(pic_save_path):
os.makedirs(pic_save_path)
browser_get()
運行結果:
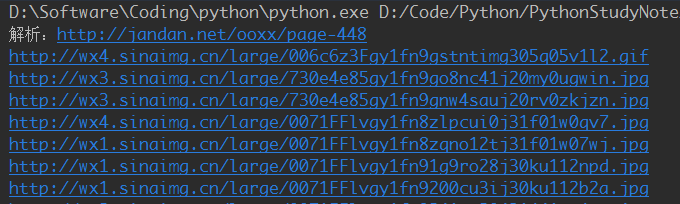
看下我們輸出文件夾~


學習Python爬蟲,日漸消瘦...
4.PhantomJS
PhantomJS沒有界面的瀏覽器,特點:會把網站加載到內存并執行頁面上的
JavaScript,因為不會展示圖形界面,所以運行起來比完整的瀏覽器要高效。
(在一些Linux的主機上沒有圖形化界面,就不能裝Chrome這類瀏覽器了,
可以通過PhantomJS來規避這個問題)。
Win上安裝PhantomJS:
- 1.官網下載:http://phantomjs.org/download.html 壓縮包;
- 2.解壓:phantomjs-2.1.1-windows.zip 放到自己想放的位置;
- 3.配置環境變量:目錄/bin 比如我的:;

- 4.打開cmd,鍵入:phantomjs --version 驗證是否配置成功;

Ubuntu/MAC上安裝PhantomJS:
sudo apt-get install phantomjs
!!!關于PhantomJS的重要說明:
在今年的四月份,Phantom.js的維護者(Maintainer)宣布退出PhantomJS,
意味著這個項目項目可能不會再進行維護了!!!Chrome和FireFox也開始
提供Headless模式(無需吊起瀏覽器),所以,估計使用PhantomJS的小伙伴
也會慢慢遷移到這兩個瀏覽器上。Windows Chrome需要60以上的版本才支持
Headless模式,啟用Headless模式也非常簡單:

selenium官方文檔也寫了:

運行的時候也會報這個警告:

5.Selenium實戰:模擬登錄CSDN,并保存Cookie
CSDN登錄網站:https://passport.csdn.net/account/login
分析下頁面結構,不難找到對應的登錄輸入框,以及登錄按鈕:
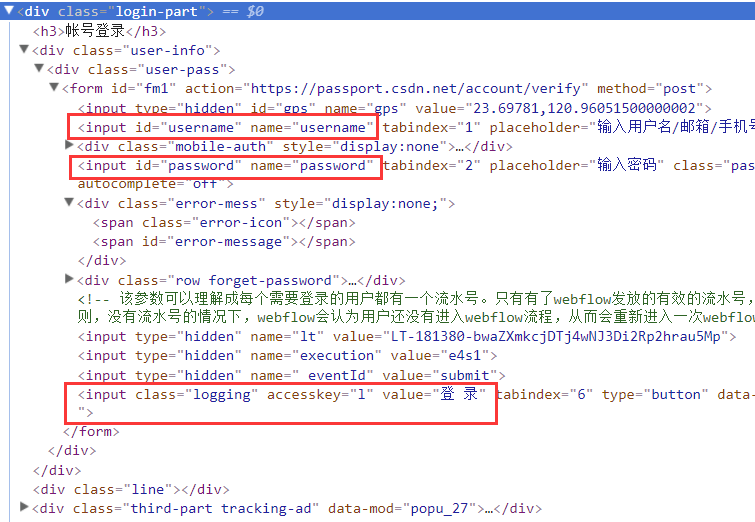
我們要做的就是在這兩個結點輸入賬號密碼,然后觸發登錄按鈕,
同時把Cookie保存到本地,后面就可以帶著Cookie去訪問相關頁面了~
先編寫模擬登錄的方法吧:

找到輸入賬號密碼的節點,設置下自己的賬號密碼,然后找到登錄
按鈕節點,click一下,然后坐等登錄成功,登錄成功后可以比較
current_url是否發生了改變。然后把Cookies給保存下來,這里
我用的是pickle庫,可以用其他,比如json,或者字符串拼接,
然后保存到本地。如無意外應該是能拿到Cookie的,接著就利用
Cookie去訪問主頁。
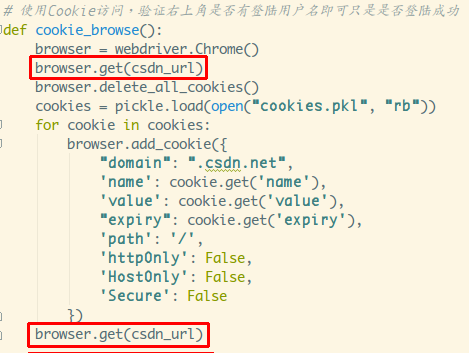
通過add_cookies方法來設置Cookie,參數是字典類型的,另外要先
訪問get一次鏈接,再去設置cookie,不然會報無法設置cookie的錯誤!
看下右下角是否變為登錄狀態就可以知道是否使用Cookie登錄成功了:

6.Selenium 常用函數
Seleninum作為自動化測試的工具,自然是提供了很多自動化操作的函數,
下面列舉下個人覺得比較常用的函數,更多可見官方文檔:
官方API文檔:http://seleniumhq.github.io/selenium/docs/api/py/api.html
1) 定位元素
- find_element_by_class_name:根據class定位
- find_element_by_css_selector:根據css定位
- find_element_by_id:根據id定位
- find_element_by_link_text:根據鏈接的文本來定位
- find_element_by_name:根據節點名定位
- find_element_by_partial_link_text:根據鏈接的文本來定位,只要包含在整個文本中即可
- find_element_by_tag_name:通過tag定位
- find_element_by_xpath:使用Xpath進行定位
PS:把element改為elements會定位所有符合條件的元素,返回一個List
比如:find_elements_by_class_name
2) 鼠標動作
有時需要在頁面上模擬鼠標操作,比如:單擊,雙擊,右鍵,按住,拖拽等
可以導入ActionChains類:selenium.webdriver.common.action_chains.ActionChains
使用ActionChains(driver).XXX調用對應節點的行為
- click(element):單擊某個節點;
- click_and_hold(element):單擊某個節點并按住不放;
- context_click(element):右鍵單擊某個節點;
- double_click(element):雙擊某個節點;
- drag_and_drop(source,target):按住某個節點拖拽到另一個節點;
- drag_and_drop_by_offset(source, xoffset, yoffset):按住節點按偏移拖拽
-
key_down:按下特殊鍵,只能用(Control, Alt and Shift),比如Ctrl+C
ActionChains(driver).key_down(Keys.CONTROL).send_keys('c').key_up(Keys.CONTROL).perform(); - key_up:釋放特殊鍵;
- move_by_offset(xoffset, yoffset):按偏移移動鼠標;
- move_to_element(element):鼠標移動到某個節點的位置;
- move_to_element_with_offset(element, xoffset, yoffset):鼠標移到某個節點并偏移;
- pause(second):暫停所有的輸入多少秒;
- perform():執行操作,可以設置多個操作,調用perform()才會執行;
- release():釋放鼠標按鈕
- reset_actions:重置操作
-
send_keys(keys_to_send):模擬按鍵,比如輸入框節點.send_keys(Keys.CONTROL,'a')
全選輸入框內容,輸入框節點.send_keys(Keys.CONTROL,'x')剪切,模擬回退:
節點.send_keys(keys.RETURN);或者直接設置輸入框內容:輸入框節點.send_keys('xxx'); - *send_keys_to_element(element, keys_to_send):和send_keys類似;
3) 彈窗
對應類:selenium.webdriver.common.alert.Alert,感覺應該用得不多...
如果你觸發了某個時間,彈出了對話框,可以調用下述方法獲得對話框:
alert = driver.switch_to_alert(),然后可以調用下述方法:
- accept():確定
- dismiss():關閉對話框
- send_keys():傳入值
- text():獲得對話框文本
4)頁面前進,后退,切換
切換窗口: driver.switch_to.window("窗口名")
或者通過window_handles來遍歷
for handle in driver.window_handles:
? ????driver.switch_to_window(handle)
driver.forward() #前進
driver.back() # 后退
5) 頁面截圖
driver.save_screenshot("截圖.png")
6) 頁面等待
現在的網頁越來越多采用了 Ajax技術,這樣程序便不能確定何時某個元素完全
加載出來了。如果實際頁面等待時間過長導致某個dom元素還沒出來,但是你的
代碼直接使用了這個WebElement,那么就會拋出NullPointer的異常。
為了避免這種元素定位困難而且會提高產生 ElementNotVisibleException的概率。
所以 Selenium 提供了兩種等待方式,一種是隱式等待,一種是顯式等待。
顯式等待:
顯式等待指定某個條件,然后設置最長等待時間。如果在這個時間還沒有
找到元素,那么便會拋出異常了。
from selenium import webdriver
from selenium.webdriver.common.by import By
# WebDriverWait 庫,負責循環等待
from selenium.webdriver.support.ui import WebDriverWait
# expected_conditions 類,負責條件出發
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.PhantomJS()
driver.get("http://www.xxxxx.com/loading")
try:
# 每隔10秒查找頁面元素 id="myDynamicElement",直到出現則返回
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
如果不寫參數,程序默認會 0.5s 調用一次來查看元素是否已經生成,
如果本來元素就是存在的,那么會立即返回。
下面是一些內置的等待條件,你可以直接調用這些條件,而不用自己
寫某些等待條件了。
title_is
title_contains
presence_of_element_located
visibility_of_element_located
visibility_of
presence_of_all_elements_located
text_to_be_present_in_element
text_to_be_present_in_element_value
frame_to_be_available_and_switch_to_it
invisibility_of_element_located
element_to_be_clickable – it is Displayed and Enabled.
staleness_of
element_to_be_selected
element_located_to_be_selected
element_selection_state_to_be
element_located_selection_state_to_be
alert_is_present
隱式等待:
隱式等待比較簡單,就是簡單地設置一個等待時間,單位為秒。
from selenium import webdriver
driver = webdriver.PhantomJS()
driver.implicitly_wait(10) # seconds
driver.get("http://www.xxxxx.com/loading")
myDynamicElement = driver.find_element_by_id("myDynamicElement")
當然如果不設置,默認等待時間為0。
7.執行JS語句
driver.execute_script(js語句)
比如滾動到底部:
js = document.body.scrollTop=10000
driver.execute_script(js)
小結
本節講解了一波使用Selenium自動化測試框架來抓取JavaScript動態生成數據,
Selenium需依賴于第三方的瀏覽器,要注意PhantomJS無界面瀏覽器過時的
問題,可以使用Chrome和FireFox提供的HeadLess來替換;通過抓取煎蛋妹子
圖以及模擬CSDN自動登錄的例子來熟悉Selenium的基本使用,還是收貨良多的。
當然Selenium的水還是很深的,當前我們能夠使用它來應付JS動態加載數據頁面
數據的抓取就夠了。
另最近天氣驟冷,各位小伙伴記得適時添衣~

順道記錄下自己的想到的東西:
- 1.不是每個網站都是像CSDN一樣不需要驗證碼就能夠登錄的,驗證碼還分幾代,
普通的數字模糊下,滑條,而像簡書掘金用那種人機檢測的是比較新的,目前還
不知道怎么解決,有知道的小伙伴告訴下唄~ - 2.像掘金,簡書等那種抓取文章,為了反爬蟲,需要登錄才能查看全文...
本節源碼下載:
https://github.com/coder-pig/ReptileSomething
本節參考文獻:
來啊,Py交易啊
想加群一起學習Py的可以加下,智障機器人小Pig,驗證信息里包含:
Python,python,py,Py,加群,交易,屁眼 中的一個關鍵詞即可通過;

驗證通過后回復 加群 即可獲得加群鏈接(不要把機器人玩壞了!!!)~~~
歡迎各種像我一樣的Py初學者,Py大神加入,一起愉快地交流學♂習,van♂轉py。

