概念
- 散列技術(shù): 在記錄的存儲(chǔ)位置和它的關(guān)鍵字之間建立一個(gè)確定的對應(yīng)關(guān)系f,使得每個(gè)關(guān)鍵字key對應(yīng)一個(gè)存儲(chǔ)位置f(key) , 通過查找關(guān)鍵字, 不需要比較就可獲得記錄的存儲(chǔ)位置;
存儲(chǔ)位置 = f(關(guān)鍵字)
- 散列表或哈希表: 采用散列技術(shù)將記錄存儲(chǔ)在一塊連續(xù)的存儲(chǔ)空間中,這塊連續(xù)存儲(chǔ)空間稱為散列表或哈希表(HashTable);
- HashTable是一種存儲(chǔ)數(shù)據(jù)的結(jié)構(gòu),就是用一個(gè)key對應(yīng)一個(gè)value,我們可以通過key來查詢這個(gè)value值。
- 通過Hash函數(shù) f(關(guān)鍵字value)計(jì)算處理,將關(guān)鍵字保存,并返回一個(gè)自定義的存儲(chǔ)位置 key;
- 查詢的時(shí)候和以上第二步計(jì)算位置的方式一樣,通過Hash函數(shù) f(關(guān)鍵字value) 返回存儲(chǔ)位置,只是在查詢的時(shí)候不用做保存數(shù)據(jù)操作而已;
- 具體可以參見:簡單HashTable原理
- Hash函數(shù):傳一個(gè)value值給這個(gè)函數(shù),這個(gè)函數(shù)對其進(jìn)行保存,并把保存的位置key返回給調(diào)用方。這是HashTable的構(gòu)造過程。
- 散列地址: 關(guān)鍵字對應(yīng)的記錄存儲(chǔ)位置, 也就是以上HashTable中所說的key;
散列技術(shù)的特性
- 既是一種存儲(chǔ)方法,也是一種查找方法;
- 數(shù)據(jù)元素之間無羅輯關(guān)系,所以不適合范圍查找,不適合查找同樣關(guān)鍵字的記錄,不適合獲取記錄的排序,最值等操作;
散列函數(shù)的構(gòu)造
- 原則:(1) 計(jì)算簡單; (2)散列地址分布均勻
直接定址法
f(key) = a*key+b; ( a,b為常量 )
- 背景: 知道關(guān)鍵字的分布;
- 取關(guān)鍵字的某個(gè)線性函數(shù)值作為散列地址;
- 特點(diǎn):簡單,均勻,不會(huì)沖突,但是事先知道關(guān)鍵字的分布情況,適合查找表小且連續(xù)。
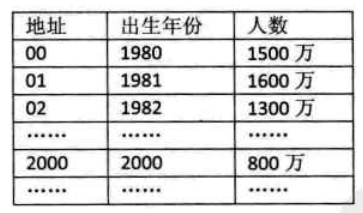
- 舉例:比如統(tǒng)計(jì)1980年以后出生的人數(shù):
-
f(key) = key-1980;
數(shù)字分析法
- 背景: 關(guān)鍵字位數(shù)多,知道關(guān)鍵字分布;
-
比如手機(jī)號,可能前幾位一樣,只是后幾位不同,抽取關(guān)鍵字的一部分計(jì)算散列存儲(chǔ)位置。事先知道關(guān)鍵字分布且若干位分布均勻。
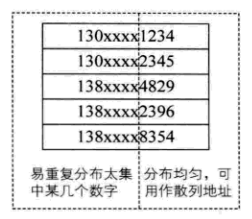
- 對手機(jī)號的后4位做特殊處理,比如:
- 翻轉(zhuǎn): 1234=>4321
- 疊加: 1234=>12+34=46,等等;
平方取中法
- 背景: 不知道關(guān)鍵字分布,且位數(shù)不是很大。
- 比如: 1234,平方1522756,抽取中間227作為散列地址。
折疊法
- 背景: 不知道關(guān)鍵字分布,位數(shù)多。
- 從左到右分割成位數(shù)相等的幾部分,這幾部分疊加求和,并按散列表表長,取后幾位作為散列地址。
- 比如: 關(guān)鍵字是 9876543210, 散列表長為3; 將關(guān)鍵字分為4組, 987 | 654 | 321 | 0 , 然后 987+654+321+0=1962, 求后三位得到散列地址為962;
除留余數(shù)法
f(key) = key mod p (p<=m)
m代表散列表長度
- p選取不好,產(chǎn)生沖突。
- 通常p為<=m(最好接近m)的最小質(zhì)數(shù)或者不包含小于20質(zhì)因子的合數(shù)。
隨機(jī)數(shù)法
f(key)=random(key)
random隨機(jī)函數(shù)
- 背景: 關(guān)鍵字長度不等。
- 當(dāng)關(guān)鍵字為字符串,轉(zhuǎn)化為某種數(shù)字來對待,比如ASCLL碼或者Unicode碼等。
散列沖突解決方法
- 沖突:關(guān)鍵字key1不等于key2,但f(key1)=f(key2)。
- 把key1和key2稱為散列函數(shù)的同義詞。
開放定址法
一旦沖突,尋找下一個(gè)空的散列地址,散列表大, 又稱"線性探測法";
fi(key) = ( f(key) + di ) MOD m (di=1,2,3...,m-1);
<img src="https://raw.githubusercontent.com/liangxifeng833/my_program/master/images/datastruct/search-hash-function-3.png" width="588" />
優(yōu)化: 二次探測法
<img src="https://raw.githubusercontent.com/liangxifeng833/my_program/master/images/datastruct/search-hash-function-4.png" width="558">
<img src="https://raw.githubusercontent.com/liangxifeng833/my_program/master/images/datastruct/search-hash-function-5.png" width="558">
還有對位移量d隨機(jī)函數(shù)計(jì)算,稱之為隨機(jī)探測法。
再散列函數(shù)法;
fi(key) = RHi(key) (i=1,2,...k)
- RHi不同散列函數(shù),隨機(jī)使用除留、折疊、平方,每次沖突換種散列函數(shù)。
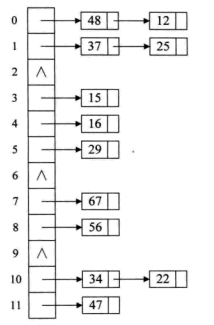
鏈地址法
- 將所有關(guān)鍵字為同義詞的記錄存儲(chǔ)在一個(gè)單鏈表(同義詞字表)中;
- 散列表中只存儲(chǔ)所有同義詞字表的頭指針;
-
缺點(diǎn): 查找時(shí)候需要遍歷單鏈表, 有性能損耗;
{12,67,56,16,25,37,22,29,15,47,48,34} mod 12
- 具體可以參見:簡單HashTable原理
公共溢出區(qū)法
- 沖突關(guān)鍵字存儲(chǔ)到溢出表中
-
以上圖有 37,48,34 是沖突的關(guān)鍵字,那么我們單獨(dú)放在另外溢出表中, 可以將基本表和溢出表定義為兩個(gè)數(shù)組;

- 散列計(jì)算后,先基本表比較。不等,到溢出表進(jìn)行順序查找。
哈希表查找
- 如果無沖突,O(1)。
- 查找平均長度取決于:
- 散列函數(shù)是否均勻
- 處理沖突的方法
- 散列表的裝填因子 裝填因子=填入表中的記錄個(gè)數(shù)/散列表長度。(表示散列表的裝滿的程度) 當(dāng)填入表中的記錄越多,裝填因子越大,產(chǎn)生沖突可能性越大。
- 通常設(shè)計(jì)散列表原則是: 將散列表空間設(shè)置的比查找集合大,犧牲空間換時(shí)間。
